
摘要:X.264編碼器" title="X.264編碼器">X.264編碼器注重實效性,在不明顯降低編碼性能的前提下,降低編碼的計算復雜度,摒棄了JM中一些耗時相對較大但對性能的提升影響很小的模塊,因此嵌入式系統中常選用X.264編碼器。移植到DSP平臺的X.264編碼器,編碼效率不佳,平均只有0.7 f/s。為了能夠在DSP平臺上進行高效率的鳊碼,采用了代碼優化以及DM642" title="DM642">DM642優化2種優化方式來優化移植到DM642平臺的X.264編碼器。對優化過后的X.264編碼器在DM642平臺上進行了實驗。實驗結果表明,優化過后的X.264編碼器對CIF格式視頻序列的編碼時間大幅度的降低。
關鍵詞:X.264;DM642;軟件流水;函數合并;EDMA
0 引言
H.264標準的全稱為“H.264/MPEG-4 part 10”,是由ITU-T和ISO/IEC共同成立的聯合視頻組(Joint Video Team,JVT)制定的新標準。H.264依然采用預測結合變換的混合編碼方案,為了在相同的編碼框架下得到更高的視頻壓縮編碼性能和更廣泛的適用性,H.264標準引入了許多新技術,如1/4,1/8像素精度的運動估計、多參考幀的幀間預測、幀內預測、環路濾波和自適應算術編碼等。H.264視頻編碼標準在編碼質量和壓縮比上比原有的視頻編碼標準都有了明顯的提高。
在相同的視覺感知質量上,編碼效率比之前的編碼方式提高了50%。H.264標準的編碼性能超越了以往所有的視頻編碼標準,具有很好的應用前景,大量的應用于視頻壓縮和視頻監控。
目前,H.264編解碼標準的研究主要分為算法研究和硬件實現兩大類,硬件實現的方案主要分為3種:
(1)基于PC平臺的方案。此方案為純軟件實現編解碼,利用MMX和SSE/SSE2等多媒體指令集來優化程序,具有開發成本低和周期短等優點。PC機的CPU體系結構并不適合處理數字信號,故CPU的有效利用率比較低。
(2)基于ASIC芯片的純硬件方案。此方案將視頻編解碼算法固化成硬件,具有集成度高和開發周期短等優點,但是專用型比較強,產品不易升級。目前市場上已經出現了H.264的編解碼芯片,如Fujitsu的MB86H51、Hisilcon的GOALTMHi3510和JVC公司的JCY0237 LSI等。
(3)基于DSP的軟硬件結合方案。此方案利用DSP芯片和其它外圍芯片來構成處理系統,具有開發靈活性高、處理能力強、開發周期低、功耗低和易升級等優點。隨著DSP性價比的不斷提高,該方案已經成為目前H.264編碼器硬件實現的理想方案。
H.264編解碼標準具有壓縮比高、適應性廣、容錯能力強和圖像恢復質量高等特點,在實時系統中具有很好的應用前景。TMS320DM642是TI公司推出的一款針對視頻和圖像處理領域應用的數字多媒體處理芯片,具有處理能力強和集成度高等特點,是目前實現H.264視頻編碼器的理想芯片之一。很多國內外公司都在開發或已經開發出了基于DM642開發視頻監控系統。
1 X.264編碼器移植
X.264是由法國巴黎中心學校的中心研究所于2004年6月發起,由許多視頻愛好者共同完成的項目,它注重實效性,在不明顯降低編碼性能的前提下,努力降低編碼的計算復雜度,摒棄了JM中一些耗時相對較大但對性能的提升影響很小的模塊,如多參考幀、幀間預測中不必要的塊模式、CABAC等。X.264編碼器在程序結構上,利用了MMX/SSE/SSE2等基于X86構架的多媒體硬件加速指令。需要將相關的X86指令屏蔽,對部分函數進行精簡,使其結構簡單易于在DSP上執行。簡單移植過后的X.264編碼器,在DM642平臺上的編碼效率極低,表1為移植過后的X.264編碼器在DM642平臺上編碼結果。

由結果可以看出,移植完成后的X.264在DM642平臺上的編碼效率非常低,只能達到平均0.6 f/s的編碼速率,需要進一步針對X.264編碼器和DM642的特性來優化以提高編碼效率。
2 X.264編碼器的優化
2.1 編碼器參數設置
X.264編碼器在VC下的優化使用了一些平臺相關的硬件加速指令,所以在VC調試下的X.264編碼器參數在DSP平臺上執行將對編碼速度產生很大的影響。在CCS中優化X.264編碼器時,在不影響編碼質量的情況下修改部分參數以提高編碼的速度。
(1)關閉環路濾波:環路濾波器能使解碼圖像的主觀質量有所提高,但環路濾波器只對提高壓縮效率做出很小的貢獻。如果采用環路濾波將降低1 ms的編碼時間。不使用環路濾波對圖像的解壓本身沒有太大影響,而DSP注重速率的情況下關閉環路濾波可以獲得更高的編碼速度。表2對有無環路濾波的編碼圖像的峰值信噪比進行了對比,從表中可以看出環路濾波對編碼的質量影響有限。

(2)對P幀使用半像素搜索,不采用1/4像素搜索。表3列出了半像素搜索與1/4像素搜索的時鐘周期對比圖。從表中可以看到,采用P幀半像素搜索方式對編碼速度提升30%以上,并且視覺上解壓出來的圖像沒有明顯失真。
(3)對全像素塊運動預測搜索的方式,X.264默認為HEX(正六邊形搜索半徑為2),在對比測試了DIA(菱形搜索,半徑為1)和UMH(可變半徑六邊形搜索)后,對比了速率和峰值信噪比后,發現在峰值信噪比相差很小的情況下DIA搜索速率最快,本文選擇DIA作為運動預測搜索方式。表4給出3種方式的對比結果:

2.2 X.264代碼優化
X.264編碼器需要有效的利用DM642的特性,如軟件流水,芯片特性和指令集等,才能有效的提高X.264編碼器在DM642平臺的編碼效率。為了X.264能夠充分的利用起DM642的特性,需要結合DM642本身的特點對移植過后的X.264代碼進行優化,才能夠提高X.264在DM642上執行的效率。
TI公司的DSP開發軟件CCS提供了功能非常強大的編譯器,編譯工具可以對代碼進行各種優化,以提高代碼的執行速度,減小代碼尺寸。這些優化包括了簡化循環、軟件流水、語句和表達式的順序重排和分配變量到寄存器。利用CCS編譯器進行優化后,仍然不能滿足視頻壓縮的需求,需要繼續對DM642上的X.264編碼器進行優化。
(1)內聯函數。內聯函數是指用函數本身來代替函數調用這一過程。當調用內聯函數時,C/C++源代碼把此函數插入到調用點,而不采用傳統的跳轉。將函數設定為內聯函數后,可以去掉復雜的函數調用過程來提高函數的執行效率,而付出的代價是增加了代碼所占用的空間。使用關鍵字inline定義內聯函數,在X.264編碼器中的預測部分對其中一個頻繁調用的函數設置為內聯。代碼如下:
static inline inI clip_uint8(int a)
(2)restrict關鍵字。為了幫助編譯器確定存儲器相關性,可以使用關鍵字restrict來限定指針、引用或數組。使用restrict關鍵字是為了確保其限定的指針在聲明的范圍內,是指向特定對象的惟一指針。編譯器在讀取函數的指針,數據時,采取保守的辦法,認為它們是相關的。這時編譯出的代碼必須執行完前次寫操作,才能開始下次讀取操作。加入restrict關鍵字后,編譯器將認為指針和數組沒有相關性,能夠并行提取數據。
(3)軟件流水。軟件流水式編排循環指令是能夠使循環的多次迭代并行執行的技術。編譯器總是力爭使用軟件流水技術。軟件流水是DSP的關鍵技術,它利用的是算法中存在的指令并行性的特點,使一個循環的多次迭代同時進行。總地來說,當使用編譯器優化的情況下,代碼尺寸小,程序性能更優。x.264代碼含有很多循環操作,故提高循環體指令的并行度使循環能夠軟件流水是提高編碼效率的有效途徑之一。
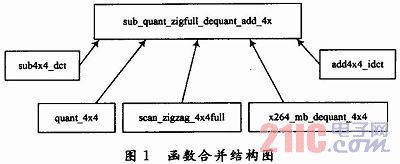
(4)函數合并。函數調用的過程中,要執行一些額外的寄存器。在編碼過程中DCT、量化、zigzag、IDCT和反量化函數調用都非常頻繁,但代碼段都很短,部分代碼只包含一個循環操作或者賦值操作。反復的調用會花費大量運行周期在函數調用上。為減少不必要的操作,提高速度,將DCT變換、量化、反量化和反DCT變化的整個過程進行優化,將幾個函數合并到一個函數中。圖1所示為合并結構。
2.3 DM642的優化
(1)CACHE優化。DM642采用了兩級CACHE的存儲器結構,兩級CACHE主要用于對程序和數據的緩存。CPU直接和一級CACHE連接,一級CACHE包括L1P(程序)和L1D(數據),大小分別為16 KB,分別占用獨立的存儲;一級CACHE的存儲速度與CPU處理速度相同。一級CACHE與二級CACHE相連,稱為L2,大小為256 kB,可以對程序和數據進行統一存取,L2 CACHE作為L1CACHE和片外存儲器之間的一個橋梁,可以由設計人員自行配置大小,分為SRAM和CACHE。L2CACHE的速度為CPU的一半。經過試驗對比,將L2分為128 kBCACHE和128 kB SRAM。將部分調用比較頻繁的函數和數據常量放在L2SRAM中,以提高讀寫速度。
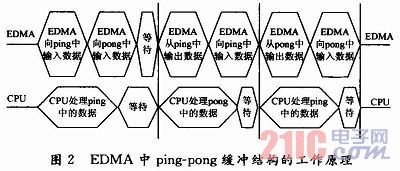
(2)EDMA。EDMA是增強的直接存儲器訪問,增加了高達64個傳輸通道,每個通道相互獨立,且通道間的優先級可以設置。CIF格式的圖像格式為352×288,一幀數據需要101 376 b,L2的CACHE容量有限,不能將所需要的參考幀和當前編碼幀都放到片內CACHE中。X.264處理的最小模塊為宏塊16×16,將當前編碼宏塊保存到片內CACHE中來提速,DSP運行的同時將片外的下一編碼宏塊傳輸到片內。采用EDMA的ping-pong緩沖技術可以對X.264編碼器的數據傳輸部分進行優化。這樣既利用了DM642片內數據存儲速度快的優點,又避免了使用較多的片內存儲空間。ping-pong緩沖結構中EDMA與CPU的工作原理如圖2所示。
3 優化結果
完成對代碼的優化過后,通過CCS的編譯將x264.out文件加載到DM642目標板上,使用了5個CIF實驗序列來測試優化過后的編碼速率。 CIF序列編碼的幀數為100幀,量化系數為28。通過CCS所提供的clock工具記錄測試序列中編碼一幀圖像所需要的CPU時鐘數。實驗測得的編碼速率數據如表5所示。

將X.264簡單DSP代碼化移植到DM642上,編碼速率很低,只有平均0.6 f/s。對比表中所示的數據可知,對于紋理簡單,運動不激烈的視頻序列,編碼幀數可達15 f/s左右,對于運動激烈,背景紋理較復雜的視頻序列,則只有10 f/s左右。通過解壓圖片可以看出,解碼后的圖像沒有發生明顯的失真。