
摘 要: 以Xilinx公司的XC4000系列FPGA(現場可編程門陣列)為例,介紹了分布式運算單元DA(Distributed Arithmetic)在高速DSP設計中的原理及實現方法。
關鍵詞: 數字信號處理 DSP FPGA FIR濾波器 FFT
隨著FPGA集成度的不斷提高,在單片FPGA中完成復雜的數字信號處理過程變成了現實。譬如:FIR濾波器、FFT以及雷達信號處理中的數字脈沖壓縮、數字鑒相等,都可以在單片FPGA中實現。在基于Xilinx XC4000系列FPGA設計的DSP中,分布式運算單元DA扮演著重要的角色。本文介紹其原理及其實現方法。
1 分布式運算單元原理
DA的運算原理非常簡單,但是它的應用卻十分廣泛。
一個線性時不變網絡的輸出可以用下式表示:

其中, y(n)為第n時刻網絡的輸出;Xk(n)為第n時刻的第k個輸入變量;Ak為第k個輸入變量的權值。
在線性時不變系統中,對于所有n時刻,Ak都是常量。如果該網絡表現為濾波器,常量Ak 即為濾波器系數,變量Xk為單一數據源的抽樣數據(如A/D的輸出)。而在時-頻轉換系統中(如離散傅立葉變換及快速傅立葉變換),常數Ak即為旋轉因子值,變量Xk為單一數據源的數據塊(多源數據的例子可以在圖像處理系統中發現)。
仔細觀察式(1)可以看出,單個輸出y(n) 需要將k個乘積累加。在以XC4000系列FPGA中的可配置邏輯功能塊(CLB)的查找表(Look-Up Table)結構[1]為基礎的DA中,這種乘積累加可以由查找表來實現。XC4000系列的CLB結構特點使得它很容易被高效的配置。
為了使得乘法之后的數據寬度不至于展寬,先把數據源數據格式規定為浮點數2的補碼形式。需要注意的是,常數Ak 不一定要進行格式轉換來匹配輸入數據的格式,它可以根據所要求的精度進行定義。
變量Xk可以用下式表示:

其中,Xkb為二進制數,即取值為0或1;Xk0為符號位,Xk0為1表示數據為負,為0表示數據為正。
將式(2)代入式(1)可以得到:

可以看出,每個方括號中進行的是輸入變量的某一個數據位和所有常數(A1~Ak)的每一位進行位與并求和。而指數部分則說明了求和結果的位權。現在就可以建立查找表來實現方括號中的操作了,其查找表用所有輸入變量的同一位進行尋址,如圖1所示。

圖1中所示的DA查找表,其寬度為對常數Ak 定義的寬度,深度為2K,K是能夠對數據源抽樣數據進行處理的數據長度,對于濾波器就表現為濾波器階數;對于FFT就表現為FFT點數。
這樣,式(1)所表示的方程就可以由加法、減法和二進制除法來實現了。但是,DA僅僅是運算方程(1)的核心,要完成式(1)還需要根據系統對時間以及FPGA資源的考慮,選擇相應的方法。
2 幾種實現方法
2.1 全并行實現方法
市場上已經有大量的通用DSP芯片,這些芯片以并行的乘法、加法運算,地址產生器和片內存儲器為主要特點,如TMS320C620x、ADSP2106x、及各種通用的FFT芯片(如PDSP16510)。為什么還要選擇FPGA呢?主要是考慮速度。要實現一個64階FIR濾波器,如果采用全并行方式,FPGA可做到50MHz的數據率,可以和系統時鐘相匹配,這是通用DSP芯片無法做到的。下面就舉出全并行的例子。
若將式(4)每個方括號之間的加法并行執行,即將每個DA查找表的輸出采用并行的加法,就得到了全并行結構。現將式(4)中的某個方括號重寫如下,并縮寫為sum:

利用式(6),可以得到一種直觀的樹形陣列,如圖2所示。
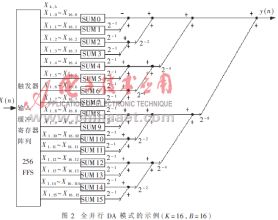
圖2中,首先要建立一個K×B位的寄存器陣列,將其輸出進行排列,用所有K個輸入數據的相同位,對DA查找表尋址,從圖中可以看出,當B=16時,輸入到輸出所需的路徑最長,該路徑為關鍵路徑,影響著電路處理的速度,在進行設計時應該注意到這點,所以應該采用流水線設計方法[1],并進行適當的約束,其數據率可以達到50MHz。圖中的15個節點代表著15個并行的加法器,中間過程的數據寬度既可以保持雙精度(B+C)位數據(C是常數Ak的寬度),也可以采用截尾的辦法得到單精度B位數據,可根據系統所要求的精度確定。
2.2 全串行實現方法
當系統對速度的要求不是很高的時候,可以用全串行設計方法,即一個DA查找表,一個并行的加法器以及簡單少量的寄存器就可達到目的,這樣能夠節省大量的FPGA資源。同樣,設K=16,B=16,將式(4)改寫如下形式:

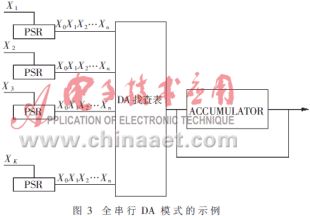
為了實現式(7),先從最低位開始,用所有K個輸入變量的最底位對DA查找表進行尋址,得到了[sum15],將[sum15]右移一位即將[sum15]乘2-1后,放到寄存器中,設為[tem15];同時,K個輸入變量的次低位已經開始對DA查找表尋址得到[sum14],右移一位后,與[tem15]相加,重復這樣的過程,直至得到[sum0],并用前面得到的累加結果減去[sum0]。要實現上述過程,需要K個長度為B的串并行轉換移位寄存器、一個容量為2K×C的DA查找表和一個累加器。該全串行電路的數據率為輸入數據抽樣頻率的1/B,即完成一次運算需要B個時鐘周期。由此可以得到全串行DA模式,如圖3所示。
2.3 串并行相結合實現方法
以上介紹的全串行方式是每個時鐘周期對所有K個變量的一位進行串行處理,全并行方式是每個時鐘周期對所有K個變量的所有B位進行并行處理;這兩種方法是針對速度優化和資源優化設計的兩種極限情況。在有些情況下,我們可以對這兩種情況進行折中考慮,獲得最佳資源利用和系統速度。我們可以從每個時鐘周期對K個變量的兩位進行處理開始著手,回顧一下式(5),并將該式改寫如下:

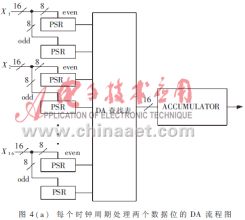
完成該式功能的功能框圖如圖4a所示。
將圖4(a)與圖3進行比較后就可以發現,圖3中的DA查找表由16個輸入變量的同一位進行尋址,而圖4(a)中的DA查找表的尋址是由16個輸入變量的連續兩位進行的,即尋址的位數由16位變成了32位。這樣,查找表的內容也需要相應的改變;而且完成一次運算也由原來的B個時鐘周期變成了需要B/2+1個時鐘周期。
下面介紹一種更易于理解的串并行混合設計方法。
將式(5)改寫成如下形式:

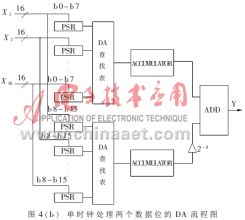
從式(9)得到流程圖如圖4(b)所示。
實現過程中應該注意DA查找表的內容,累加之前要乘2-1,注意進位等。
從以上給出的兩種串并行結合的設計方法可以看到,只要將式(5)進行適當的變換,還有其它的硬件實現方法,這里就不一一敘述了。
下面給出在K=8、B=16的情況下,不同的DA查找表所占用的資源。Xilinx公司的XC4000系列FPGA的一個CLB可以實現32×1大小的RAM,在圖4(a)中所描述的DA查找表占用2,048個CLB,而在圖4(b)中所描述的兩個DA查找表只占用256個CLB。用一片XC4025即可完成后者,其數據率可達到16MHz。
 ?
? 
綜上所述,由于分布式運算單元的應用,改變了傳統的設計觀念,為基于FPGA的DSP設計提出了新的思路,必將在高速的FIR濾波器設計、高速FFT設計中得到廣泛的應用。隨著FPGA集成規模的不斷提高(Xilinx公司Virtex系列已經達到了百萬門級),許多復雜的數學運算已經可以由FPGA來實現,單片FPGA實現系統的設想即將變為現實。
參考文獻
1 蔣亞堅,沈桂明. FPGA在雷達信號處理器中的應用研究. 雷達與對抗. 1999(2):57~63
2 The Programmable Logic Data Book. Xilinx, 1999