
本文給出了采用這些技術的高速環境狀態機設計的規范及分析方法和優化方法,并給出了相應的示例。
為了使FPGA或CPLD中的狀態機設計滿足高速環境要求,設計工程師需要認識到以下幾點:寄存器資源和邏輯資源已經不是問題的所在,狀態機本身所占用的FPGA或CPLD邏輯資源或寄存器資源非常小;狀態機對整體數據流的是串行操作,如果希望數據處理的延時非常小,就必須提高操作的并行程度,壓縮狀態機中狀態轉移的路徑長度;高速環境下應合理分配狀態機的狀態及轉移條件。本文將結合實際應用案例來說明。

狀態機設計規范

1. 使用一位有效的方式進行狀態編碼
狀態機中狀態編碼主要有三種:連續編碼(sequential encoding)、一位有效(one-hot encoding)方式編碼以及不屬于這兩種的編碼。例如,對于一個5個狀態(State0~State4)的狀態機,連續編碼方式狀態編碼為:State0-000、State1-001、State2-010、State3-011、State4-100。一位有效方式為下為:State0-00001、State1-00010、State2-00100、State3-01000、State4-10000。對于自行定義的編碼則差別很大,例如試圖將狀態機的狀態位直接作為輸出所需信號,這可能會增加設計難度。
使用一位有效編碼方式使邏輯實現更簡潔,因為一個狀態只需要用一位來指示,而為此增加的狀態寄存器數目相對于整個設計來說可以忽略。一位有效至少有兩個含義:對每個狀態位,該位為1對應唯一的狀態,判斷當前狀態是否為該狀態,只需判斷該狀態位是否為1;如果狀態寄存器輸入端該位為1,則下一狀態將轉移為該狀態,判斷下一狀態是否為該狀態,只需判斷表示下一狀態的信號中該位是否為1。
2. 合理分配狀態轉移條件
在狀態轉移圖中,每個狀態都有對應的出線和入線,從不同狀態經不同的轉移條件到該狀態的入線數目不能太多。以采用與或邏輯的CPLD設計來分析,如果這樣的入線太多則將會需要較多的乘積項及或邏輯,這就需要更多級的邏輯級聯來完成,從而增加了寄存器間的延遲;對于FPGA則需要多級查找表來實現相應的邏輯,同樣會增加延遲。狀態機的應用模型如圖1所示。
狀態機設計的分析方法
狀態機設計的分析方法可以分為兩種:一種是流程處理分析,即分析數據如何分步處理,將相應處理的步驟依次定為不同狀態,該方法能夠分析非常復雜的狀態機,類似于編寫一個軟件程序的分析,典型設計如讀寫操作和數據包字節分析;另一種方法是關鍵條件分析,即根據參考信號的邏輯條件來確定相應的狀態,這樣的參考信號如空或滿指示、起始或結束、握手應答信號等。這兩種分析方法并沒有嚴格的界限,在實際的狀態機設計分析時往往是這兩種方法結合使用。下面分別說明這兩種分析方法。
1. 流程處理分析
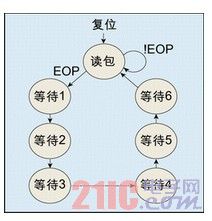
例如,在一個讀取ZBT SRAM中數據包的設計中,要根據讀出的數據中EOP(End of Packet)信號是否為1來決定一個包的讀操作是否結束,由于讀取數據的延后,這樣就會從ZBT SRAM中多讀取數據,為此可以設計一個信號VAL_out來過濾掉多讀的數據。
根據數據到達的先后及占用的時鐘周期數,可以設計如圖2所示的狀態機(本文設定:文字說明及插圖中當前狀態表示為s_State[n:0],為狀態寄存器的輸出;下一狀態next_State[n:0],為狀態寄存器的輸入;信號之間的邏輯關系采用Verilog語言(或C語言)中的符號表示;#R表示需要經過一級寄存器,輸出信號對應寄存器的輸出端)。該狀態機首先判斷是否已經到達包尾,如果是,則依次進入6個等待狀態,等待狀態下的數據無效,6個等待狀態結束后將正常處理數據。
2. 關鍵條件分析
圖3為一個路由器線卡高速數據包分發處理的框圖,較高速率的數據包經過分發模塊以包為單位送往兩個較低速率數據通路(即寫入FIFO1或FIFO2)。
對于分發模塊設計,關鍵參考信號是EOP及快滿信號AF1、AF2,參考EOP可以實現每次處理一個包,參考AF1、AF2信號可以決定相應的包該往哪個FIFO中寫入。分發算法為:FIFO1未滿(AF1=0),數據包將寫入FIFO1;如果FIFO1將滿且FIFO2未滿(AF1=1,且AF2=0),則下一數據包將寫入FIFO2;如果FIFO1、FIFO2都將滿(AF1=1且AF2=1),則進入丟包狀態。狀態機描述如圖4所示:UseFifo1狀態下數據包將寫入FIFO1,UseFifo2狀態下數據包將寫入FIFO2,丟包狀態下數據包被丟棄,提供丟包計數使能DropCountEnable。
狀態機的進一步優化
1. 利用一位有效編碼方式
如前所述,狀態機的工作頻率跟狀態機中各個狀態對應的不同轉移條件的入線數目有關。如果到一個狀態的轉移條件相同但入線數非常多,其邏輯實現很可能并不復雜。在一位有效編碼方式下,對于某個狀態,如果其他所有狀態經相同的轉移條件到該狀態,那么其邏輯實現可以很好地化簡。
例4:一位有效編碼方式下狀態位s_State[n:0]中,
s_State[1] | s_State[2] | ... | s_State[n]=1與 s_State[0]=1等價,那么
next_State[0]=(s_State[0]&S) | (s_State[1]&T) | (s_State[2]&T) | ... | (s_State[n]) 可以化簡為:
next_State[0]=(s_State[0]&S) | ((~s_State[0])&T),右端輸入信號數目大大減少。
2. 利用寄存器的使能信號
多數FPGA或CPLD寄存器提供使能端,如果所有的狀態機轉移必須至少滿足某個條件,那么這個條件可以通過使能信號連接實現,從而可以降低寄存器輸入端的邏輯復雜度。如上例中不同狀態間轉移必須以EOP為1作為前提,因而可以將該信號作為使能信號來設計。
3. 結合所選FPGA或CPLD內部邏輯單元結構編寫代碼
以Xilinx FPGA為例,一個單元內2個4輸入查找表及相關配置邏輯可以實現5個信號輸入的最復雜的邏輯,或8~9個信號的簡單邏輯(例如全與或者全或),延時為一級查找表及配置邏輯延時;如果將相鄰單元的4個4輸入查找表輸出連接到一個4輸入查找表,那么可以實現最復雜的6輸入邏輯,此時需要兩級查找表延時及相關配置邏輯延時。更復雜的邏輯需要更多的級連來實現。針對高速狀態機的情況,可以盡量將狀態寄存器輸入端的邏輯來源控制在7個信號以內,從而自主控制查找表的級連級數,提高設計的工作頻率。
4. 通過修改狀態機
如果一個狀態機達不到工作頻率要求,則必須根據延時最大路徑修改設計,通常的辦法有:改變狀態設置,添加新狀態或刪除某些狀態,簡化轉移條件及單個狀態連接的轉移數目;修改轉移條件設置,包括改變轉移條件的組合,以及將復雜的邏輯改為分級經寄存器輸出由寄存器信號再形成的邏輯,后者將會改變信號時序,因而可能需要改變狀態設置。
5. 使用并行邏輯
很多情況下要參考的關鍵信號可能非常多,如果參考這些關鍵信號直接設計狀態機所得到的結果可能很復雜,個別狀態的出線或入線將會非常多,因而將降低工作頻率。可以考慮通過設計并行邏輯來提供狀態機的關鍵信號以及所需的中間結果,狀態機負責維護并行邏輯以及產生數據處理的流程。并行邏輯應分級設計,級間為寄存器,從而減少寄存器到寄存器的延時。
一個使用并行邏輯的狀態機,該設計用于使用單一數據總線將FIFO1~4中的數據發送到4個數據通路上去,該設計中并行邏輯產生每次操作時的通路及FIFO選擇結果,狀態機負責控制每次操作的流程:在“Idle”狀態下,如果FIFO1~4中有數據包供讀取,則進入“Schedule”狀態;獲得調度結果后“Schedule”經過一個“Wait”狀態,然后進入“ReadData”狀態讀取數據,同時開始計數,計數到達所指定數值或者讀到數據包尾時進入空閑狀態“Idle”,依次循環下去。
流水線設計
流水線(Pipelining)設計是將一個時鐘周期內執行的邏輯操作分成幾步較小的操作,并在較高速時鐘下完成。圖6a中邏輯被分為圖6b中三小部分,如果它的Tpd為T,則該電路最高時鐘頻率為1/T,而在圖6b中假設每部分的Tpd為T/3,則其時鐘頻率可提高到原來的3倍,因而單位時間內的數據流量可以達到原來的三倍。代價是輸出信號相對于輸入滯后3個周期,時序有所改變(圖6b中輸出信號的總延時與圖6a中一樣,但數據吞吐量提高了),同時增加了寄存器資源,而FPGA具有豐富的寄存器資源。
本文所強調的通過減少寄存器間的邏輯延時來提高狀態機的工作頻率,與流水線設計的出發點一樣,不同的是流水線所強調的是數據處理時的數據通路優化,而本文所強調的是狀態機中控制邏輯的優化。