
摘 要: 為了減少網絡中的不良信息對青少年造成的危害,設計了一種臟字過濾的軟件,可以發現那些網頁內容中含有的不良信息,便于網絡管理員對網絡文化的維護。
關鍵詞: Java;臟字;過濾器;設計
良好的網絡文化對培養青少年的愛國意識、創新精神、促進青少年良好的個性發展以及文化學習等方面都有積極的作用。但是網絡文化中混雜著種種不良因素,對青少年造成許多負面影響:網絡中的不健康內容不利于青少年的成長,甚至造成許多青少年犯罪行為的不斷發生;網絡世界的虛擬性還會造成青少年對現實社會的不滿,青少年對網絡世界的過分迷戀會導致網絡孤獨,網絡中多元化的內容會導致青少年認識偏差,網絡的隱匿性容易使青少年道德弱化[1]。特別令人擔憂的是不良的網絡文化對青少年的犯罪起著推動作用,值得全社會關注和重視。
本文提出了一種臟字過濾器軟件的設計,對網絡中不良的內容進行查找、發現,避免這些不良網絡文化侵蝕青少年的心靈健康。
1 臟字過濾器的設計原理
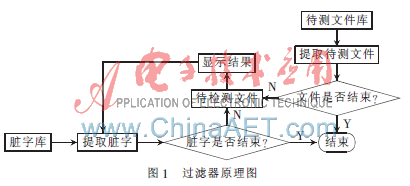
臟字過濾器的原理圖如圖1所示。其原理如下:(1)對臟字庫的內容進行分割,把臟字庫中所有的臟字或詞組分開,并把這些臟字或詞組存入數組中;(2)將待測文件庫中的文件進行逐個讀取,并記錄文件的內容;(3)在待測文件中查找是否存在剛存放臟字或臟詞組內容的數組里面的內容,如果有,進行標注等操作;如果沒有,繼續檢查待測文件庫中的下一個待測文件,直到待測文件庫中的待測文件都被檢查完為止;(4)輸出結果。即輸出待測文件庫中每個待測文件中包含臟字或臟詞組的個數及出處等信息。
2 算法實現
軟件開發環境:myeclipse平臺,Java語言。首先以myeclipse平臺新建一個java project,在新建的project中需要導入下面相關文件:
import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
過濾器軟件中main函數的主要內容如下:
public static void main(String[] args) {
BufferedReader br=new BufferedReader(new InputStreamReader(System.in));
String ans=null;
int cnt=0;//字庫中關鍵詞個數
int number=0;//臟字出現次數
String filepath="D:\\臟字待測文件庫";
//待檢測文件路徑,此文件夾下可以放若干個待檢測的文件
String fileLibrarypath="D:\\臟字典\\file.txt";
//臟字庫文件的存放路徑
File file = new File(filepath);
try {
//讀入用戶輸入的回車鍵信息
System.out.println("請按回車鍵,查看過濾信息:");
String str = null;
str = br.readLine();
if (str != null) {
if (!file.isDirectory()) {
System.out.println("待檢測文件路徑
不對,請修改路徑。");
} else if (file.isDirectory()) {
ans=getcontent(fileLibrarypath);
int k;
StringTokenizer sst=new
StringTokenizer(ans, "|");
k = sst.countTokens();
String[] record = new String[k];
while (sst.hasMoreElements()) {
record[cnt] = sst.nextToken();
cnt++;
}
String[] filelist = file.list();
for (int i = 0, flen = filelist.length; i
< flen; i++){
String temp = filepath +
"\\" + filelist[i];
number = searchkeyword(record,
cnt, temp);
System.out.println("第"+(i+1) +"文件中臟字出現的次數:" + number);
//字庫中關鍵詞個數
}
} else {
//提示用戶按回車鍵
System.out.println("你還沒有輸入回
車鍵信息");
}
}
} catch (IOException e) {
e.printStackTrace();
}
//輸出查詢結果
if (ans != null) {
System.out.println("字庫中關鍵詞個數:"+ cnt);//字庫中關鍵詞個數
System.out.println("臟字庫內容如下:"+ ans);
} else {
System.out.println("沒有可以匹配的信息");
//輸出臟字庫中的內容
}
}
//得到指定路徑文件中的內容
private static String getcontent(String filepath) {
String all = "";
File file = new File(filepath);
try {
if (!file.isFile()) {
System.out.println("文件路徑不對,請修改路徑");
} else {
File readfile = new File(filepath);
BufferedReader br = new BufferedReader(new FileReader(readfile));
String ss = br.readLine();
while (ss != null) {
all = all + ss;
//all中存放讀取的文件內容信息
ss = br.readLine();
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return all;
}
//在待測文件中匹配臟字出現的次數
private static int searchkeyword(String[] str, int cnt, String filepath){
int number = 0;
String s = "";
s = getcontent(filepath);
for (int i = 0; i < cnt; i++) {
if (s.indexOf(str[i]) > -1) {
number++;
}
}
return number;
}
至此,完成了臟字過濾器軟件代碼的編寫工作,接下來可以進行run操作,即可以得到待測文件庫中的待測文件包含臟字次數及出處等相關信息的結果。
3 實驗結果分析
臟字庫的存放路徑:D:\臟字典\file.txt;臟字庫文件中的內容略。
待測文件庫的存放路徑:D:\臟字待測文件庫;文件庫中存放了三個文件,分別為:test1.txt、test2.txt、test3.txt。
運行該過濾器軟件后,得出的檢測結果如圖2所示。

由圖可以看到把待測文件中臟字及臟詞組出現的次數全部顯示出來,結果與實際情況完全一致。
本文設計的臟字過濾器軟件,已在myeclipse環境下通過Java語言實現,并對整個過濾器軟件進行了測試,測試結果顯示該設計完全可以達到對網頁文件中的臟字進行過濾,還能指出這些臟字的數目及其出處。為網絡管理員的管理帶來方便,并給網絡管理方面的編程人員提供了一個良好的開發平臺。
參考文獻
[1] 周偉文,侯建華.網絡改變了什么:青少年的網絡生存[M].石家莊:河北人民出版社,2005:292-294.