
摘 要: 隨著Internet等技術的飛速發展,信息處理已經成為人們獲取有用信息不可或缺的工具,如何在海量信息中高效地獲得有用信息至關重要,因此自動文本分類技術尤為重要。現有的文本分類算法在時間復雜性和空間復雜性上遇到瓶頸,不能滿足人們的需求,為此提出了基于Hadoop分布式平臺的TFIDF算法,給出了算法實現的具體流程,通過MapReduce編程實現了該算法,并在單機和集群模式下進行了對比實驗,同時與傳統串行算法進行了對比。實驗證明,使用TFIDF文本分類算法可實現對海量數據的高速有效分類。
關鍵詞: 文本分類;MapReduce;并行化;TFIDF算法
當今信息時代,數據膨脹的速度已遠遠超過人工分析它們的能力,如何在海量數據中快速地獲得所需信息至關重要,因此自動文本分類技術尤為重要。文本分類是指依據文本內容由計算機根據某種自動分類算法,把文本判定為預先定義好的類別[1]。文本分類是數據挖掘的關鍵技術,為了提高分類質量,首先要實現算法并行化。
近幾十年來,一系列統計學習文本分類方法被提出[2],國內外對文本分類算法的研究很多,但大都存在一些局限性,特別是缺乏對海量文本數據的挖掘。云計算的出現為算法并行化帶來了新的契機,很多科研人員和機構都在投入研究云計算。Hadoop平臺發布以來,很多專業人員致力于利用它對海量數據進行挖掘,目前已經實現了一些基于該平臺的算法。本文研究TFIDF文本分類算法,并通過MapReduce編程,在單機和集群模式下研究TFIDF算法的并行化并進行實驗驗證,并與傳統算法進行對比實驗, 實驗表明,改進的算法提高了分類速度,有效地解決了海量數據的分類問題。
1 TFIDF算法的實現
TFIDF是一種用于資訊檢索與資訊探勘的常用加權技術。在某一個特定的文檔中,詞頻(TF)指某一具體給定的詞語在這個文檔中出現的次數。對于在某一特定文檔里的詞語ti,其詞頻可以表示為:

TFIDF算法是有監督的文本分類算法,它的訓練集是已標記的文檔,并且隨著訓練集規模的增大,分類效率、精度均顯著提高[6]。
2 MapReduce編程模型
分布式文件系統(HDFS)和MapReduce編程模型是Hadoop的主要組成部分。Hadoop是一個能夠對大數據進行分布式處理的框架,能夠把應用程序分割成許多小的工作單元,并且把這些單元放到任何集群節點上執行[7]。MapReduce模型的計算流程如圖1所示。
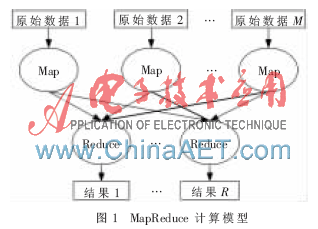
分布式文件系統主要負責各節點上的數據的存儲,并實現高吞吐的數據讀寫。MapReduce計算模型的核心部分是Map和Reduce兩個函數[8]。Map的輸入是in_key和in_value,指明了Map需要處理的原始數據。Map的輸出結果是一組<key,value>對。系統對Map操作的結果進行歸類處理。Reduce的輸入是(key,[value1… value m])。Reduce的工作是將相同key的value值進行歸并處理最終形成(key,final_value)的結果,所有的Reduce結果并在一起就是最終結果。其中HDFS和MapReduce的關系如圖2所示。

3 MapReduce編程模型下的TFIDF算法
3.1 TFIDF算法流程
Hadoop分布式計算的核心思想就是任務的分割及并行運行。從TFIDF 的計算公式可看出, 它非常適合分布式計算求解。詞頻(TF)只與它所在文檔的單詞總數及它在此文檔出現的次數有關。因此,可以通過數據分割, 并行統計出文檔中的詞頻TF,加快計算速度。得到單詞詞頻TF 后,單詞權重TFIDF 的計算取決于包含此單詞的文檔個數。因此,只要能確定包含此單詞的文檔個數,即能以并行計算的方式實現TFIDF的求解。MapReduce下計算TFIDF 的整個處理流程如圖3所示。主要包括統計每份文檔中單詞的出現次數、統計TF及計算單詞的TFIDF值三個步驟。

Hadoop對數據進行的是分塊處理,并且默認數據塊大小為64 MB,所以當存在很多小數據文件時,反而降低了運行速度,因此對小數據集Hadoop的優越性體現得并不明顯。但是隨著數據集增大,傳統算法所需要的時間急劇增長,而應用了Hadoop框架的TFIDF算法所需要的時間只是呈線性增加,表現出了一定的算法優越性。
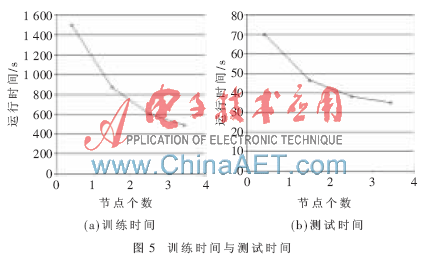
(3)不同節點數下的對應運行時間
圖5(a)和(b)分別顯示了Sogou文本分類語料庫隨著節點數目由1增加到4時的訓練時間和測試時間曲線。
本文通過在Hadoop平臺下的MapReduce編程,對傳統TFIDF算法進行了性能優化,并通過3組對比實驗,驗證了改進的TFIDF算法可取得更好的分類結果,可以很好地實現對海量數據的高效挖掘。
參考文獻
[1] SEBASTIANI F.Text categorization[Z].Encyclopedia of Database Techologies and Applications,2005:683-687.
[2] Yang Yiming.An evaluation of statistical approaches to text categorizationg[J].Journal of Information Retrieval,1999,1(1/2):67-68.
[3] 謝鑫軍, 何志均.一種單一表單工作流系統的設計和實現[J].計算機工程,1988,24(9):53-55.
[4] 王宇.基于TFIDF的文本分類算法研究[D].鄭州:鄭州大學,2006.
[5] 向小軍,高陽,商琳,等.基于Hadoop平臺的海量文本分類的并行化[J].計算機科學,2011,38(10):190-194.
[6] 搜狐研發中心.Sogou文本分類語料庫[OL].(2008-09)[2012-09-30].http://www.sogou.com/labs/dl/c.html.
[7] 劉鵬.實戰Hadoop-開啟通向云計算的捷徑[M].北京:電子工業出版社,2011.
[8] 李彬.基于Hadoop框架的TF- IDF算法改進[J].微型機與應用,2012,31(7):14-16.