
摘 要: 隨著互聯網的發展,各種類型的應用層出不窮,網站訪問量越來越大、內容越來越多,用戶與系統的交互不斷增強,訪問集中,造成數據庫負載過大,網站顯示延遲等影響。緩存技術就是解決此問題的一種方案,緩存技術以其簡單的設計、高效的存儲性能得到了越來越廣泛的應用,而內存數據庫則是一種優秀的緩存解決方案。主要介紹Redis的特性以及在系統中的應用。
關鍵詞: Redis; 高速緩存; 內存數據庫
隨著 Internet 技術的快速發展,網絡接入速度不斷提高,各種類型的應用層出不窮,網站訪問量越來越大、內容越來越多,用戶交互不斷增強,訪問集中,造成數據庫負載過大、網站顯示延遲等影響,而造成影響用戶體驗的主要瓶頸集中在數據庫服務器承載能力方面。要讓數據庫服務器快速響應并能夠承受越來越大的負載, 緩存技術就是解決此問題的一種方案。Cache性能高效,設計簡單,可以對數據庫中的數據進行緩存,降低數據庫負載;可以對Web頁面進行緩存,提高Web頁面響應速度;對復雜計算結果進行緩存,可以減少網站服務器的傳輸負荷和計算速度和對用戶的響應速度,有效地提高網站性能及可擴展性。本文主要介紹開源內存數據Redis的特性及其應用。
1 Redis簡介
Redis是一種 Key-Value類型的內存數據庫產品,全名為遠程字典服務(REmote DIctionary Server),與Memcache 相似,但Redis 支持更多的數據類型,包括字符串(String)、鏈表(List)、集合(set)、有序集合(Zset)、哈希(Hash)等。與Memcached一樣,為了保證效率,Redis數據都是緩存在內存中,但與Memcache 只是用來做緩存相比,Redis適用的場景更多,并且可以直接用于數據存儲服務。
2 Redis特性
雖然Redis與Memcaehed具有很多相似的特征,可替代Memcaehed做為緩存,但它又具有更多優秀的特性,如支持多種數據結構、支持簡單事務控制、支持持久化、支持主從復制、Virtual Memory功能等。
2.1 Redis數據類型
Redis除了提供常規的數值或字符串外還提供4種數據類型:List、Set、Zset(Sorted Set)和Hset(Hash Set)。
(1)String(字符串)
Strings數據結構是簡單的Key-Value類型,Value其實不僅是String,也可以是數字。使用Strings類型,可以完全實現目前 Memcached 的功能,并且效率更高;還可以享受Redis的定時持久化、操作日志及Replication等功能。
(2)List(雙向鏈表)
Lists就是鏈表,使用Lists結構可以輕松地實現最新消息排行等功能。Lists的另一個應用就是消息隊列,可以利用Lists的PUSH操作將任務存在Lists中,隨后工作線程再用POP操作將任務取出進行執行。Redis還提供了操作Lists中某一段的API,可以直接查詢、刪除Lists中某一段的元素。
(3)Set(集合)
Sets是一個集合,集合的概念就是一堆不重復值的組合。Set是String類型的無序集合。Redis還為集合提供了求交集、并集、差集等操作,可以非常方便地實現如共同關注、共同喜好、二度好友等功能,對上面的所有集合操作還可以使用不同的命令選擇將結果返回給客戶端還是存集到一個新的集合中。
(4)Zset(有序集合)
Zset與Set相似,但在Set的基礎上增加了一個Score的屬性。這一屬性在添加修改元素時進行指定,每次指定后,Zset會自動按新的值重新調整順序。
(5)Hash(hash表)
在Memcached中,經常將一些結構化的信息打包成hashmap,在客戶端序列化后存儲為一個字符串的值,比如用戶的昵稱、年齡、性別、積分等,在需要修改其中某一項時,通常需要將所有值取出反序列化后,修改某一項的值,再序列化存儲回去。這樣不僅增大了開銷,也不適用于一些可能并發操作的場合(比如兩個并發的操作都需要修改積分)。而Redis的Hash結構可以實現像在數據庫中Update一個屬性一樣只修改某一項屬性值。
2.2 Redis事務控制
Redis可以通過MULTI/EXEC來支持簡單的事物控制。Redis只能保證事務中的所有命令串行執行,在事務的執行過程中不會為其他客戶端發起的請求提供服務。當一個client使用multi命令時,這個連接會進入一個事務上下文,該連接后續的命令會放在一個隊列中,當此連接收到exec命令后,Redis會順序地執行隊列中的所有命令,但是如果事務中的一個命令失敗了,并不回滾其他命令。
2.3 Redis持久化機制
Redis是一個能支持持久化的內存數據庫,它通過將內存中的數據保存到磁盤來持久化。Redis有兩種持久化方式,一種是Snapshotting(快照),另一種是append-only file(縮寫aof)的方式。下面分別介紹:
(1)Snapshotting方式
快照是默認的持久化方式。這種方式是將內存中數據以快照的方式寫入到二進制文件dump.rdb中。可以通過配置redis.conf來設置自動做快照持久化的方式。
(2)aof方式
如果對數據要求很高,可以采用aof持久化方式。因為在使用aof持久化時,Redis會將每個命令都追加到appendonly.aof文件中,當Redis出現意外關閉后,重啟后會通過執行appendonly.aof文件中的命令來在內存中重建整個數據[1]。
2.4 主從復制
Redis主從復制配置非常簡單,可以通過配置redis.conf文件中的Replication段來實現主從復制。 Redis主從復制特點:
(1)支持一個master可以擁有多個slave,同時slave還可以接收其他的slave。
(2)主從復制不會阻塞master和slave,在同步數據時,master和slaver都可以接收client請求。
通過主從復制的特性可以做到以下3個方面:
(1)可以做到讀寫分離,提供系統伸縮性和系統性能,如master主服務用來寫數據,slave服務用來讀數據。
(2)可以做到備份數據分離,如slave服務器群中的一個或兩個服務器用來備份數據。
(3)雖然Redis宣稱主從復制無阻塞,但是由于Redis使用單線程服務,而與slave的同步是由線程統一處理,因此,對性能有影響。在slave第一次與master做同步時,如果master快照文件較大,相應快照文件的傳輸將耗費較長時間,文件傳輸過程中master會造成訪問延遲。
2.5 Virtual Memory 功能
Redis的Virtual Memory(虛擬內存)通過配置可以讓用戶設置最大使用內存,當超出這個內存時,通過LRU類似算法,將一部分數據存入文件中,在內存中只保存使用頻率高的數據來提高Redis性能。
3 Redis應用分析
通過上述Redis 的特征分析,可以看到當作Cache工具時,Redis與其他Cache相比更多的優勢性能和內存使用效率相差無幾卻擁有更多的數據結構并支持更豐富的數據操作,同時還支持持久化。例如在某博客系統中,整個系統結構圖如圖1所示,客戶端通過Redis proxy訪問Redis。目前的Redis本身都不具備分布式集群特性,當有大量 Redis時,通常只能通過客戶端的一些數據分配算法(比如一致性哈希)來實現集群存儲。而 Twemproxy 通過引入一個代理層,可以將其后端的多臺 Redis實例進行統一管理與分配,使應用程序只需要在 Twemproxy 上進行操作,而不用關心后面具體有多少個真實的 Redis存儲,這樣就可以通過平行擴展Redis Master服務器來無限擴展Redis。
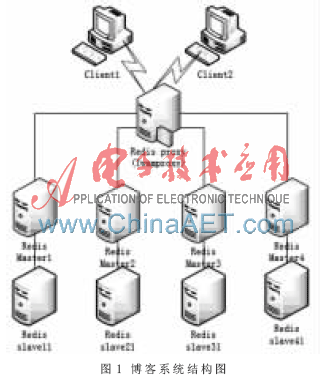
Redis-Master1與Redis-slave11通過主從復制連接。同時,Redis-Slaver11通過aof負責持久化。Twemproxy可以配置結點故障問題,當某一個結點出現故障后,用Redis Master相應的Redis Slave切換成Master。
在系統運行中要處理各種業務邏輯,因而需要訪問大量的數據庫資源,在數據庫上進行讀寫操作,數據庫壓力會較大,性能較低。通常把更新不頻繁的數據進行緩存。例如下面幾種操作。
(1)根據條件得到最新數據的操作,以時間為權重
比較典型的取最新博文的數據代碼如圖2所示。可以將最新的5 000條博客的ID放在Redis的雙向鏈表(list)集合中,使用LPUSH globle:blogpostids命令向雙向鏈表(list)集合中插入數據,插入完成后再用LTRIM global.latest.blogs 0 5000命令使其永遠只保存最近5 000個ID,然后在客戶端獲取最新博文時可以用下面的邏輯(偽代碼)了。如果還有其他的取最新數據需求,比如“模擬技術”分類的最新50條數據,則可以再建一個按此分類的雙向鏈表(list),將博文的ID插入此雙向鏈表(list)中。

(2)根據條件得到排行榜應用,相當于數據中取TOP N操作,例如訪問量最高的博文、用戶的相互關注等。
以某個條件為權重得到數據,如果博文按瀏覽的次數排序,這時可以使用sorted set將瀏覽次數值設置成sorted set的score,將具體的博文ID設置成相應的value,每次新增博文時只需要執行一條ZADD blog:getblogpostrank 0 1000,每當博文被瀏覽時,使用ZINCRBY blog:getblogpostrank 1 1000,取訪問量最高的博文時就可以使用ZREVRANGE blog:getblogpostrank 0 -1,來按照瀏覽次數高低排行了。
(3)網站計數的應用,比如在博客系統中瀏覽次數、評論數等。
Redis的命令都是原子性的,可以使用INCRBY、ZINCRBY命令來增加計數,使用DECRBY、ZINCRBY命令來減少計數。如果給博文ID號為1 000的增加一次瀏覽,則使用INCRBY blogpost:1000 1命令。
(4)構建反垃圾信息(spam)系統,比如評論系統中的反垃圾信息等。
在博客系統中評論是必不可少的,同時各種攻擊spam也少不了(如垃圾評論、廣告、刷排名等),可以針對這些spam制定一個規則,例如一分鐘評論不得超過2次,5分鐘不能評論多于5次。這可以使用Redis的Sorted Set來將最近一天用戶操作記起來。使用系統時間為score,這樣執行一條ZADD user:1000:operation 54561227854“發表評論”,得到用戶最近一分鐘的操作如下ZRANGEBYSCORE user:1000: operation 54561227854 +inf。這樣如果一分鐘有兩次評論,就可以判定為spam(每個網站的規則不一樣)。
(5)可以使用Redis系統中Pub/Sub和Ajax長鏈接來構建實時消息系統。
Redis的Pub/Sub系統作為一種消息通信模式,類似于設計模式中的觀察者模式,發布和訂閱機制可以很方便地實現簡單的聊天功能,可以應用于實時聊天(通過與Ajax長鏈接)、異步消息處理(如注冊后給用戶郵件通知)等場景。將不同的頻道分布到不同服務器上,也可以很方便地實現服務器的擴展以應對用戶量的增長。
(6)使用List或者Zset構建隊列系統。
可以使用List構建隊列系統,加入隊列可以使用rpush global:queue addblogpost,退出隊列使用lpop global:queue。使用Zset來構建有優先級的隊列系統,加入普通級別的列隊命令zadd global:zqueue 1 addblogpost,加入高優先級的列隊可以通過提高score的值來提高優先級。
為了高速緩存在系統應用的不同需求,對Redis 的主要特征進行了分析,同時對其作為緩存解決方案的應用進行了舉列說明。隨著Redis的發展,官方roadmap在Redis 3版本中將加入集群功能,Redis作為內存數據庫,可以通過水平擴展來延伸系統的物理內存,同時又支持持久化,完全可以將所有數據存放在Redis內存數據庫中,這樣才能充分發揮內存數據庫的優勢。
參考文獻
[1] Xhan.redis學習筆記之持久化[EP/OL].[2011-02-07](2013-03-15).http://www.cnblogs.com/xhan/archive/
2011/02/07/1949640.html.