
摘? 要: 對(duì)二維條碼" title="二維條碼">二維條碼PDF417的基本概念、用途、優(yōu)勢(shì)做了系統(tǒng)的介紹,著重分析了PDF417條碼的具體譯碼過(guò)程,并給出該條碼作為多進(jìn)制碼,進(jìn)行R-S糾錯(cuò)譯碼時(shí)所要注意的有關(guān)域運(yùn)算及模運(yùn)算。
關(guān)鍵詞: PDF417條碼? 有限域? 錯(cuò)誤糾正容量? 錯(cuò)誤位置多項(xiàng)式
?
條碼的使用,極大地提高了數(shù)據(jù)采集和信息處理的速度,改善了人們的工作和生活環(huán)境,提高了工作效率,為管理的科學(xué)化和現(xiàn)代化作出了很大貢獻(xiàn)。
受信息容量的限制,一維條碼的使用不得不依賴于后臺(tái)的數(shù)據(jù)庫(kù)。在沒有數(shù)據(jù)庫(kù)或不便聯(lián)網(wǎng)的地方,一維條碼的使用便受到了局限。為此,美國(guó)Symbol公司發(fā)明了一種被稱作便攜數(shù)據(jù)文件" title="數(shù)據(jù)文件">數(shù)據(jù)文件的二維條碼——PDF417條碼。
1 PDF417條碼簡(jiǎn)介
PDF417是一種具有高密度、高容量的便攜式數(shù)據(jù)文件,它能容納大量信息而不需要與外部數(shù)據(jù)庫(kù)相連。一個(gè)PDF417符號(hào)能容納1千字節(jié)數(shù)據(jù),是尺寸同樣大小的一維條碼的百倍。通過(guò)使用PDF417,諸如人員信息、檔案信息、發(fā)貨標(biāo)簽、裝船清單、設(shè)備校準(zhǔn)信息、機(jī)動(dòng)車登記等立即變成機(jī)器可識(shí)讀的標(biāo)識(shí)。
PDF417條碼具有一個(gè)顯著的優(yōu)點(diǎn)便是糾錯(cuò)能力強(qiáng),它采用了目前世界上最先進(jìn)的錯(cuò)誤糾正技術(shù)。這種隱含子符號(hào)在內(nèi)的錯(cuò)誤糾正技術(shù),不僅可以有效地防止譯碼錯(cuò)誤,提高譯碼的速度及可靠性;而且可以將由于條碼符號(hào)破損、沾污等丟失的信息破譯出來(lái)。錯(cuò)誤糾正可分為八個(gè)等級(jí),當(dāng)?shù)燃?jí)為八時(shí)最高,可以將符號(hào)受損面積達(dá)50%的條碼符號(hào)所含的信息復(fù)現(xiàn)出來(lái)。
圖1為PDF417碼符號(hào)結(jié)構(gòu)。符號(hào)的頂部和底部為空白區(qū)。上下空白區(qū)之間為多行結(jié)構(gòu)。每行的數(shù)據(jù)符號(hào)字符數(shù)相同,行與行左右對(duì)齊直接銜接。
?

?
圖2為符號(hào)字符的結(jié)構(gòu)。每一符號(hào)由4個(gè)條和4個(gè)空構(gòu)成,自左向右從條開始。每一個(gè)條或空包含1~6個(gè)模塊。在一個(gè)符號(hào)字符中,4個(gè)條和4個(gè)空的總模塊數(shù)為17。
?

?
2 譯碼的具體過(guò)程
譯碼的具體過(guò)程如圖3所示。
?
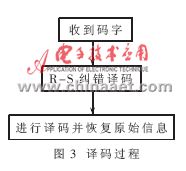
?
2.1 條碼的糾錯(cuò)譯碼
PDF417條碼在識(shí)讀過(guò)程中,由于條碼圖案的損壞,或掃描及掃描后的數(shù)據(jù)傳輸出錯(cuò),會(huì)出現(xiàn)突發(fā)錯(cuò)誤。Reed-Solomon" title="Reed-Solomon">Reed-Solomon碼特別適合糾正突發(fā)錯(cuò)誤。故采用R-S碼進(jìn)行糾錯(cuò)譯碼。
R-S碼是一類具有很強(qiáng)糾錯(cuò)能力的多進(jìn)制BCH碼,其譯碼步驟主要分為三步:
第一步由收到碼字R(x)計(jì)算d-1個(gè)伴隨式分量sj;第二步由伴隨式求錯(cuò)誤位置多項(xiàng)式,得出錯(cuò)誤圖樣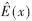 ;第三步由R(x)-
;第三步由R(x)-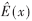 得出最可能發(fā)送的碼字
得出最可能發(fā)送的碼字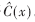 。
。
其中錯(cuò)誤圖樣包括隨機(jī)錯(cuò)誤(既不知錯(cuò)誤位置,又不知錯(cuò)誤大小)和刪除錯(cuò)誤(知道錯(cuò)誤所在位置,不知錯(cuò)誤大小)。在求刪除錯(cuò)誤時(shí),二進(jìn)制BCH碼的糾錯(cuò)糾刪譯碼很簡(jiǎn)單。把收到的R(x)中刪除位置全填上0,并送到譯碼器譯碼。但多進(jìn)制碼必須對(duì)伴隨式進(jìn)行修正。該伴隨式包含兩個(gè)錯(cuò)誤位置多項(xiàng)式:一是刪除位置多項(xiàng)式,另一是錯(cuò)誤位置多項(xiàng)式。總的錯(cuò)誤位置多項(xiàng)式等于二者的乘積。
2.2 條碼譯碼過(guò)程
417條碼碼字集包含929個(gè)碼字:0~928。所謂碼字集即一種條形碼制中所給定的數(shù)據(jù)字符的范圍。
碼字0~899:用于表示數(shù)據(jù)(根據(jù)當(dāng)前的壓縮模式" title="壓縮模式">壓縮模式和GLI解釋),每個(gè)碼字表示一個(gè)或多個(gè)數(shù)字、字母或符號(hào)。
碼字900~928:900、901、902、913、924用于各壓縮模式標(biāo)記;925、926、927用于GLI(全球標(biāo)識(shí)標(biāo)記符,不同的GLI具有相應(yīng)的碼字解釋);922、923、928用于宏417碼(當(dāng)文件內(nèi)容太長(zhǎng),無(wú)法用一個(gè)417條碼符號(hào)表示時(shí),可用包含多個(gè)宏417條碼的分塊表示);921用于條碼識(shí)讀器初始化;903~912,914~920保留待用。
為了有效地壓縮并表示數(shù)據(jù),PDF417采用三種數(shù)據(jù)壓縮模式設(shè)置來(lái)組成字符集。
2.2.1 文本壓縮模式(TC)
碼字為900時(shí)鎖定該模式,分管大寫字母型子模式、小寫字母型子模式、混合型子模式、標(biāo)點(diǎn)型子模式。通過(guò)標(biāo)準(zhǔn)字符集所對(duì)應(yīng)的特定數(shù)值可以完成各子模式間的切換,可進(jìn)行轉(zhuǎn)移切換(即只對(duì)切換后的第一個(gè)碼字有限,隨后返回),亦可進(jìn)行鎖定切換(該模式切換到下一個(gè)切換前一直有效)。
每種子模式選擇文件中出現(xiàn)頻率較高的一種字符組成的字符集。在子模式中,GLI標(biāo)準(zhǔn)規(guī)定了文本壓縮模式下每個(gè)字符所對(duì)應(yīng)的值(0~29),一個(gè)字符對(duì)對(duì)應(yīng)一個(gè)單獨(dú)的碼字:
碼字=30×H+L
式中:H、L依次表示字符對(duì)中的高位和低位字符值。
任何模式到文本壓縮模式(TC)的鎖定都是到大寫字母型子模式的(Alpha)鎖定。在文本壓縮模式中,每一個(gè)碼字用兩個(gè)基為30的值表示(范圍為0~29)。如果在一個(gè)字符串的尾部有奇數(shù)個(gè)基為30的值,需要用值為29的虛擬字符ps填充最后一個(gè)碼字。算法如下:
(1)收到碼字/30,商為高位字符值,余數(shù)為低位字符值;
(2)由字符值確定是哪種子模式;
(3)查找該子模式下,字符值對(duì)應(yīng)的文本值,恢復(fù)原始信息。
2.2.2 字節(jié)壓縮模式(BC)
當(dāng)所要表示的字節(jié)總數(shù)不是6的倍數(shù)時(shí),用碼字901鎖定;否則用924鎖定,碼字913轉(zhuǎn)移為該模式,通過(guò)基256至基900的轉(zhuǎn)移,將2位十六進(jìn)制的數(shù)據(jù)序列轉(zhuǎn)換為碼字序列。算法如下:
(1) 用924鎖定模式
例如:一個(gè)2位十六進(jìn)制的數(shù)據(jù)序列01H,02H,03H,04H,05H,06H (H代表十六進(jìn)制)
1×256e5+2×256e4+3×256e3+4×256e2+5×256+6=1×900e4+620×900e3+89×900e2+74×900+846
從而表示為一個(gè)碼字序列:924,1,620,89,74,846
(2)用901鎖定模式
????前6字節(jié)的轉(zhuǎn)換方法同上,剩下的每字節(jié)對(duì)應(yīng)一個(gè)碼字,依次直接表示數(shù)列:01H,02H,03H,04H,05H,06H,07H,08H,04H
轉(zhuǎn)換為一個(gè)碼字序列:901,1,620,89,74,846,7,8,4
????將收到的每5個(gè)mod900的碼字轉(zhuǎn)換為十進(jìn)制數(shù),繼而轉(zhuǎn)換為6個(gè)mod256數(shù),分別按十六進(jìn)制的數(shù)輸出。若碼字個(gè)數(shù)非6的倍數(shù),則將碼字個(gè)數(shù)被6整除后余下的mod900的碼字直接按十六進(jìn)制輸出。
2.2.3 數(shù)字壓縮模式(NC)
碼字為902時(shí)鎖定該模式,通過(guò)基10至基900的換算,實(shí)現(xiàn)數(shù)據(jù)位數(shù)的壓縮,能把約3個(gè)數(shù)字位用一個(gè)碼字表示。當(dāng)數(shù)字位數(shù)大于13,用數(shù)字壓縮模式;數(shù)字位數(shù)小于13,用文本壓縮模式。算法如下:
(1)每15個(gè)碼字從左到右分為一組(每15個(gè)碼字可轉(zhuǎn)換為44個(gè)數(shù)字位),其最后一組碼字可少于15個(gè)。
(2)對(duì)于每一組碼字先執(zhí)行基900至基10的轉(zhuǎn)換,然后去掉前導(dǎo)位1。
2.2.4 譯碼的總體流程
???? 譯碼的總體流程圖如圖4所示。
?
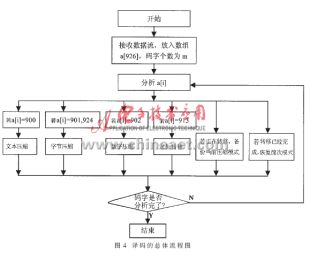
?
3 有關(guān)PDF417譯碼過(guò)程中的幾個(gè)關(guān)鍵問(wèn)題
3.1 有關(guān)域的運(yùn)算
PDF417條碼碼字集包含929個(gè)碼字,即碼字取值范圍為0~928,故譯碼始終在有限域GF(929)中進(jìn)行,超出GF(929)域的項(xiàng)必須通過(guò)mod(929)轉(zhuǎn)化到GF(929)中。
錯(cuò)誤糾正碼字δ>-929,在有限域GF(929)中的負(fù)值等于該值的補(bǔ)數(shù);如果δ<=-929,在有限域GF(929)中的負(fù)值=余數(shù)(δ/929)的補(bǔ)數(shù)。
3.2 從已知的簡(jiǎn)單模2算法到PDF417需用的模929算法方案的實(shí)現(xiàn)
3.2.1 本原元與本原多項(xiàng)式
GF(929)中的所有元素均能由3生成,故PDF417碼的本原元為3,而GF(929)中以3為根的最小多項(xiàng)式為
m(x)=x-3
故該式為PDF417碼的本原多項(xiàng)式。
3.2.2 求逆運(yùn)算
在GF(929)中所有的除法均通過(guò)求逆得到。求逆即:
xix-i=1? --->? x-i為xi的逆(x為本原元)。
域中元素通過(guò)GF(929) <---> 3i mod929轉(zhuǎn)換為3i(i=0,1,...927)。求逆后再次通過(guò)上式,轉(zhuǎn)換至GF(929)中,即:
GF(929)--->ximod929--->x-imod929--->GF(929)
二維條碼PDF417技術(shù)在國(guó)內(nèi)的使用正處于上升階段。它數(shù)據(jù)容量更大,超越了字母數(shù)字的限制,條碼相對(duì)尺寸小" title="尺寸小">尺寸小,具有抗損毀能力,不再需要后臺(tái)數(shù)據(jù)庫(kù)的支持,應(yīng)用范圍非常廣泛。同時(shí)用戶可以根據(jù)需要進(jìn)行前端加密,從而提高條碼的保密性和防偽性。一些大廠商、大企業(yè)、大銀行或是政府性質(zhì)的部門等實(shí)力雄厚的單位是二維條碼的主要使用單位。如果將此技術(shù)進(jìn)一步推廣,市場(chǎng)前景將非常可觀。
本算法已通過(guò)軟件實(shí)現(xiàn)。
?
參考文獻(xiàn)
1 王新梅.糾錯(cuò)碼與差錯(cuò)控制.北京:人民郵電出版社,2001.4:242~293
2 R.E.Blahut,徐秉錚譯.差錯(cuò)控制碼的理論與實(shí)踐.廣州:華南理工大學(xué)出版社,1988
3 S.Lin,T.Kasam.Encoding and decoding of reed-solomon?codes in dual basis.電子學(xué)報(bào),1986;(4):6~20
4 曹志剛,錢亞生.現(xiàn)代通信原理.北京:清華大學(xué)出版社,1992:332~364