
文獻標識碼: A
文章編號: 0258-7998(2011)08-0052-04
AVS標準是我國第一個擁有自主知識產權的數字音視頻編解碼標準,其編碼效率比國際標準MPEG-2高2~3倍,與MPEG-4/H.264相當,但算法復雜度及存儲要求比H.264明顯低,更便于硬件的實現。
逆掃描、反量化與反變換模塊在AVS視頻解碼過程中占有很重要的位置,其算法與架構實現優劣對AVS解碼器的性能有很大的影響,國內外學者對這3個模塊進行了研究。本文為了提高AVS解碼器的處理速度,綜合了國內外學者的設計思想提出了一種逆掃描、反量化與反變換模塊結構,在消耗邏輯資源允許的情況下提高了處理速度,做到速度和面積的平衡。
本文將逆掃描、反量化和反變換模塊結合在一起進行設計,在實現了塊內部優化的同時采用了乒乓緩存寄存器組來實現塊之間流水線,提高了速度;采用寄存器組復用技術實現逆塊掃描中寄存器組與反變換中的轉置寄存器組的復用,節省了寄存器資源。
1 硬件結構
根據AVS解碼標準,本文提出了一種高效簡潔的逆掃描、反量化與反變換系統結構,該結構主要由四部分組成。反量化模塊完成量化系數向變換系數的轉變;逆掃描與寄存器組選擇模塊根據逆掃描表完成變換系數的存儲;寄存器組用來存儲變換系數及反變換中的轉置數據;反變換模塊將變換系數轉換成殘差樣值,為后續的重構做好準備。硬件結構及數據流程如圖1所示。

其中輸入為VLD模塊解析出的(run,level)對、塊結束標志及一些模式判別的信息。反量化模塊對Level數據進行反量化,逆掃描與寄存器組選擇模塊采用依據輪流使用的規則產生寄存器組選擇信號,同時對Run進行累加,并根據累加結果查表得到需要存儲的寄存器,等所有量化后的Level值存儲完畢后,由It_start信號連續讀取8次寄存器進入反變換模塊,反變換模塊采用內部流水線結構經過22個時鐘周期處理完一個塊。反變換模塊中的轉置寄存器復用了前端的寄存器組。
本設計通過乒乓結構實現了塊與塊之間的流水。圖2是本設計的總體時序安排,圖中考慮到變換編碼后一個塊內的有效系數一般小于25。其中以一個塊數據輸入反量化模塊作為起始時刻,當反變化模塊讀取一個寄存器組并將其作為轉置寄存器使用時,另一個寄存器組用于存儲下一個塊的反量化結果。如圖2,寄存器組1用來存儲當前塊反量化后的變換系數值,而寄存器2被用于上一個塊的反變換中。另外,讀取轉置后的數據時,通過對移位最初的寄存器賦零對寄存器2清零,從而用于下一個塊的變換系數的存儲。

1.1 逆掃描與寄存器組選擇模塊
該模塊先對Run值進行累加,并根據掃描方式查表,得到當前Level值所對應的寄存器號,控制將反量化后的變換系數存入相應寄存器中,重復以上工作直到讀到塊結束標志。當前塊不為零的所有變換系數均根據逆掃描表存儲在相應的位置,因為每次從寄存器中讀取轉置數據時都會對寄存器清零,為下次使用做好準備,所以對于變換系數為零的情況就不用單獨存儲,從而提高了設計的處理速度。
1.2 反變換模塊
反變換模塊是將當前塊的變換系數矩陣轉換為殘差樣值矩陣的一個過程,為了節約硬件成本,此設計采用一維變換和轉置矩陣實現二維變換,參考文獻[2]中提出了一種快速有效的方法,本文對其方法進行了優化,節約了不必要的硬件資源和時鐘。
下面主要介紹一維變換過程。
設AVS的一維反變換的輸入輸出變量分別為:
X=[X0,X1,X2,X3,X4,X5,X6,X7]T
Y=[Y0,Y1,Y2,Y3,Y4,Y5,Y6,Y7]T
根據Y=T8×X,把8個輸出元素展開成以下組合,其中T8為8×8的反變換矩陣。
M0=8X0+8X4;M1=8X0-8X4
M2=4X1+4X5;M3=9X1-10X5
M4=6X1+2X5;M5=2X1+9X5
M6=10X2+4X6;M7=4X2-10X6
M8=9X3+2X7;M9=2X3+6X7
M10=10X3-9X7;M11=4X3+4X7
其中所有的乘法均可化為移位操作,再定義8個中間變量N0~N7:
N0=M0+M6;N1=M2+M8+M4
N2=M1+M7;N3=M3-M9
N4=M1-M7;N5=M4-M10
N6=M0-M6;N7=M5-M11-M9
重新整理后得到的輸出:
Y0=N0+N1;Y1=N2+N3;Y2=N4+N5;Y3=N6+N7
Y4=N6-N7;Y5=N4-N5;Y6=N2-N3;Y7=N0-N1
由以上算法可以看出,一維反變換模塊只需要移位和加法操作,既方便硬件實現還節省了硬件資源。經計算此一維反變化模塊共需要40個加法器。
反變換模塊的時序見圖2,第1時鐘周期進行并行讀取數據,2個時鐘周期進行一維反變換,第4個時鐘周期開始向轉置矩陣中存入一維反變換后的數據,第12周期開始讀取轉置矩陣中的數據,第15個時鐘周期開始輸出數據,第22個時鐘周期結果輸出完畢。
1.3 寄存器組復用
在逆塊掃描順序中,一些后續的系數可能需要在一開始時就準備好,而一些在前面次序的系數則可能在后續的時間使用,所以只有一個塊的所有數據都存儲完成后,才能進行后續的反變換,故至少要對一個塊的變換系數進行存儲。為了提高處理速度,后續的反變換模塊中將采用并行流水線輸入,因此存儲模塊此時不能采用有時序限制的RAM,本文采用了寄存器組實現。同時為了消除塊數據的準備延時,還采用了乒乓結構,即在設計中用了兩個寄存器組,這樣就可在處理當前一個塊系數的同時,用另一個寄存器組來存儲下一個塊反量化后的數據。
在反變換中也需要用到轉置存儲。為了節省資源,本設計采用了寄存器復用技術,即反變換中用到的轉置矩陣與逆掃描后用于存儲變換系數的矩陣復用,具體復用方法如圖3所示。
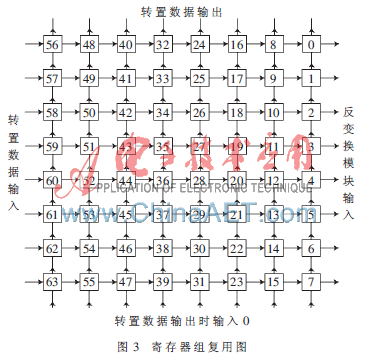
以上為一個寄存器組,包含64個13 bit的寄存器。最后一列為反變換模塊輸入,即當一個塊變換系數根據逆掃描順序存儲完后,連續8個時鐘周期讀取寄存器組最后一列,在每個時鐘周期向反變換模塊并行輸入8個13 bit的數據。第一列為轉置數據輸入端。考慮到反變換流水線及復用的問題,在連續2個時鐘周期讀取寄存器組最后一列輸入到反變換模塊后,轉置數據開始從第一列輸入,這樣可以滿足反變換內部的流水線問題,也可以達到寄存器復用的目的。第一行為轉置數據的輸出,最后一行在轉置數據輸出時賦值為零,這樣可以使轉置輸出和寄存器賦零同時進行,從而可以減少不必要的時鐘周期和資源。
2 仿真結果及分析
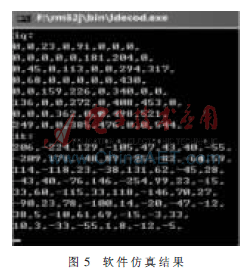
根據上述思想,采用Verilog HDL語言對算法進行了RTL級電路描述,并采用Altera公司的軟件Quartus II 8.0 對此算法進行了實現和仿真驗證,并將仿真結果與rm52j軟件的輸出結果進行了比較。Quartus II仿真結果如圖4所示,波形圖給出了一個塊的反量化和反變換輸出結果。rm52j的輸出結果如圖5所示,比較可見輸出結果相同。

本設計采用的是自頂向下和自下而上的混合設計方法,逆掃描、反量化和反變換過程是AVS系統中的一個模塊,局部的測試很難判斷出該模塊是否可以應用到整個解碼系統中去,所以此模塊亦在自己搭建的基于SoPC的AVS驗證平臺上進行了驗證。加入此模塊前,軟件處理一幀碼流時間與用此硬件模塊代替軟件模塊后的解碼時間如圖6所示,通過計算可知解碼速度提高約15%。

變換編碼后一個塊內的有效系數一般小于25,所以逆掃描、反量化的時鐘一般小于25個時鐘周期,而反變換的時鐘周期為22個,所以處理一個塊的時鐘周期大約為25個,大大提高了速度。由于寄存器的復用及設計的優化,節省了硬件資源,本設計采用的FPGA為EP2C35F672C6,資源使用情況如圖7所示,可見使用的總的LE為3 059個。

本文對AVS逆掃描、反量化和反變換算法進行了研究,并對目前其他學者在這方面取得的成果進行分析驗證,實際考慮了AVS解碼器整體設計的可行性,提出了一種速度更快、資源占用更少的方法。本設計為了解決RAM讀寫時序限制的影響,采用了兩組寄存器陣列代替RAM實現乒乓操作,同時為了減少硬件資源,采用寄存器組復用技術,即反變換中的轉置矩陣與逆掃描后存儲寄存器組復用。最后給出了波形仿真結果,并與rm52j的輸出結果比較,驗證了結果的正確性。通過在基于Nios II的SoPC系統上進行測試,證明該設計能夠正確快速實現逆掃描、反量化及反變換功能。
參考文獻
[1] GB/T 20090.2006.信息技術 先進音視頻編碼2部分:視頻[S].2006.
[2] 張璐,劉佩林.基于FPGA的AVS反變換的設計與實現[J]. 電視技術,2006(7):20-23.
[3] 毛訊.高速視頻解碼器設計研究[D].杭州:浙江大學,2001.
[4] 趙策,劉佩.AVS游程解碼、反掃描、反量化和反變換優化設計[J].信息技術,2007(2):54-57.
[5] 黃友文,陳詠恩.AVS反掃描、反量化和反變換模塊的一種優化設計[J].計算機工程與應用,2008,44(19):93.
[6] H.264及AVS視頻解碼器中 IQ/IDCT的設計與實現[J].電子技術應用,2006,32(7):39-42.