
文章標識碼: A
文章編號: 0258-7998(2012)02-0124-03
近年來,機器人聽覺系統開發已經成為機器人研究領域的重要課題。由于聲波的波長較大,具有較強的衍射能力,可以繞過障礙物傳播,并且能與視覺傳感器配合,從而可用于實現移動機器人的全方位導航。聽覺系統的開發本質上就是聲源定位系統的研究,采用麥克風陣列進行聲源定位是信號處理領域的一個研究熱點。一組麥克風按照一定的幾何結構擺放組成麥克風陣列[1],拾取來自各個方向的聲音信號,并進行空時處理,從而精確定位目標聲源。
在工程應用中,根據麥克風陣列模型和聲音球面傳播模型構建的聲源定位系統是一組復雜的非線性方程,難以用數值計算方法準確建模。在這種情況下,可以應用神經網絡表達這種非線性系統。神經網絡可以按照指定的精度逼近各種復雜的非線性系統,解決非線性系統的建模問題,并對信息采用分布式存儲的處理方式,具有高運算效率和很強的容錯性、魯棒性[2-3]。
本文研究了可應用移動機器人上的聲源定向系統,介紹了其硬件構成,采用BP神經網絡對定向系統進行研究,并通過Matlab仿真證明了在四元麥克風陣列模型下實現遠場和近場的目標聲源定向。
1 定向系統硬件結構
1.1 麥克風陣列模型
聲源定向系統的幾何結構如圖1所示,由M1、M2、M3和M4 4個麥克風組成一個四元球面陣列,對目標聲源進行定向。其中P為聲源,?琢、?茁分別為方位角和俯仰角。系統麥克風選用駐極體麥克風,這種傳聲器具有體積小、全向性、價格低、靈敏度較高和頻率響應范圍寬等優點。該麥克風能夠有效地收集聲音信息并檢測出聲音到達麥克風的初始時刻,為后續的定位計算提供準確的數據。整個系統以Activmedia的Pioneer3 AT機器人為安裝平臺,如圖2所示。該機器人配備有速度、激光、攝像頭等傳感器,采用4個車輪保持平衡,可以承受的載重超過35 Kg,底部裝有2個直流電動機,分別用來驅動左輪和右輪,前后均裝配了防碰接觸開關,能同時適用于戶外和戶內的應用需求。
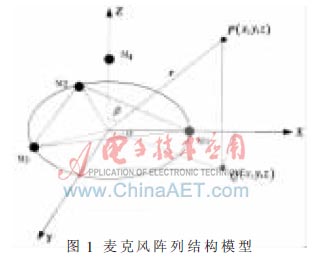
圖1 麥克風陣列結構模型

圖2 機器人實驗系統平臺
1.2 聲達時間獲取
1.2.1 信號放大及噪聲的處理
由于全向型麥克風的輸出電壓大都在零到幾十毫伏之間,如此微弱的電信號無法滿足后期信號處理工作的要求。因此,僅靠電容式麥克風的拾音能力是遠遠不夠的,有必要對麥克風采集到的信號進行放大。本文采用性能較穩定的集成運算放大器對采集信號進行二級放大。考慮到電器元件的放大特性不是完全一致的,因此加入了增益調整電位器,以便后期調試時減少由于硬件特性不同而產生的誤差。除此之外,為了在實驗過程中實時觀測信號的采集情況,利用發光二極管制作輸出信號指示燈來指示信號的強弱變化。同時考慮到聽覺定位系統的魯棒性和實時性,本文還利用集成運算放大器制作電壓比較器,使聽覺定位系統具有一定的抗噪能力,通過調節參考電壓對背景噪聲進行過濾。
1.2.2 聲達時間點的捕捉
通過上述過程,系統對聲電信號進行了整形,使得大于背景噪聲的信號以方波的形式輸出,用于捕捉聲源信號到達時間點。為了使陣列中各個麥克風均能精確地捕捉目標聲音到達的時間點,采用微處理器配合RS觸發器進行捕捉,具體實現方法如圖3所示。
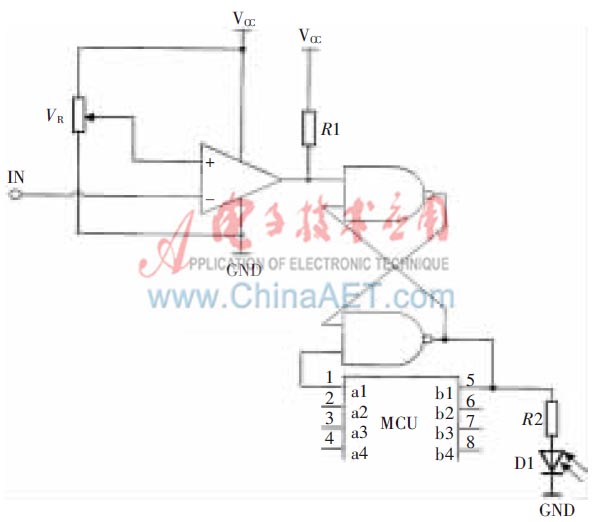
圖3 捕捉聲達時間點硬件電路圖
聲源信號經過電壓比較器整形后,產生連續方波脈沖。當第一個脈沖到達觸發器時,觸發器鎖存并保持電平,輸出端發光二極管隨即發生變化,指示聲源信號起始點已被鎖存。由于已將微處理器中的可編程計數器調整為捕捉定時器工作模式,并設置CPU時鐘頻率,所以當觸發器改變電平時,CPU記錄并存儲脈沖到來的時間。等待4路麥克風的聲源信號相繼到達后,再利用串口通信將4個存儲的時間點發送到上位機,與此同時,將鎖存器電平和微處理器復位,等待下一刻聲源信號的到達。這種利用硬件直接捕捉聲達的方法簡單易行且精度較高。
2 神經網絡計算模型建立
2.1確定網絡結構
BP神經網絡是一種多層前饋神經網絡,由輸入層、隱含層和輸出層組成[4]。根據系統輸入輸出數據的特點來確定BP神經網絡的輸入輸出,輸入數據為3個時延值,即聲音信號到達陣列中不同位置的麥克風的時間差。把聲源到麥克風M4的時間作為基準,到麥克風M1、M2、M3的時間與基準的差記作3個時延值,構成一組3個參數的輸入數據。輸出數據為目標聲源的位置,本文的聲源定位目的是為了實現移動機器人對目標聲源的跟蹤,所以輸出數據采用球坐標形式較為方便。該網絡的輸出有方位角、俯仰角和距離3個參數。
隱含層層數的選擇要從網絡的精度和訓練時間上綜合考慮[5],在網絡精度達到要求的情況下,可以選擇單隱層,以求加快訓練速度;而對于復雜的映射關系,選擇多隱含層,可以提高網絡預測精度[6-7]。本文選用有2個隱含層的BP網絡,網絡結構為3-25-25-3,即輸入層和輸出層有3個節點,2個隱含層分別有25個節點。
2.2 數據處理
假設4個麥克風之間的距離均為0.1 m,目標聲源范圍為一個半徑0.1 m~5 m的球體內的任意點。聲速為340 m/s,根據聲源定位模型的幾何關系隨機取數得到系統2 000組的輸入輸出數據。從中隨機選取1 900組數據作為網絡訓練數據,其余100組數據作為網絡測試數據。
數據歸一化方法是神經網絡預測前對數據常做的一種處理方法[8]。該方法主要有最大最小法、平方數方差法[9]兩種。本文采用第一種方法對輸入輸出數據進行歸一化處理,并對網絡預測輸出進行反歸一化,通過Matlab的自帶函數mapminmax來實現。
3 Matlab仿真與結果分析
3.1 Matlab仿真
Matlab軟件中包含Matlab神經網絡工具箱,可以直接調用構建各種類型的神經網絡。本文的BP神經網絡主要用newff、train和sim 3個神經網絡工具箱自帶函數來實現網絡的構建、訓練和仿真預測。
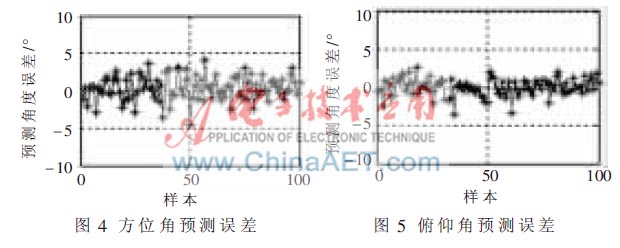
本文的聲源定位系統以實現對目標聲源的跟蹤為目的,預測出方位角和俯仰角,確定目標聲源的空間方向實現跟蹤。但由于BP神經網絡的擬合能力有限,并不能對距離做出較為準確的預測,故舍去了這組數據,主要分析方位角和俯仰角這2組輸出數據。圖4為100組預測數據的方位角預測誤差,誤差范圍為±5°。圖5為100組預測數據的俯仰角預測誤差,誤差范圍為±4°。
3.2 仿真結果分析與實驗驗證
傳統的聲源定位方法是利用幾何關系,建立一組時延和聲源坐標的方程組,通過解方程組得到時延和聲源坐標的數值關系。在解方程組的過程中,大都假設聲源位于遠場且聲音信號以平面波傳播,以此來約減得到近似結果。但當聲源位于近場時,即當麥克風之間的距離相對于聲源到麥克風的距離較大時,這種假設就不再成立了。如果仍然用近似的結果進行計算,那么得到的數據與真實數據相比就不僅是誤差較大了,而是錯誤的。
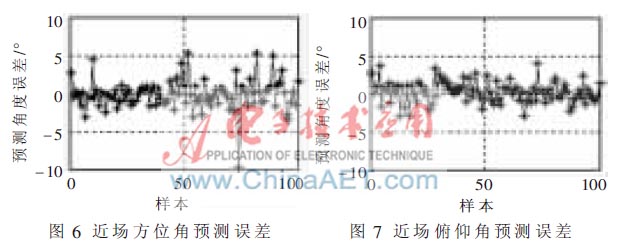
用于BP神經網絡預測的100組輸入輸出數據是在2 000組樣本數據中隨機選擇的,遠場和近場的聲源位置都有。從Matlab仿真得到的圖形來看,誤差分布較均勻,說明并沒有因為是近場聲源神經網絡就出現大的預測誤差,表明該神經網絡無論是近場還是遠場都可以預測目標聲源的方位角和俯仰角。為了進一步驗證網絡在近場對聲源的定向情況,選取目標聲源范圍為0.1 m~0.5 m的空心球體內的點,用已訓練好的BP網絡再次進行預測。預測的方位角誤差和俯仰角誤差分別如圖6、圖7所示。近場方位角預測誤差大部分在±5°以內,有個別樣本點的誤差較大甚至預測錯誤,這是由于選取的樣本點離坐標原點太近造成的,不影響實際應用。近場俯仰角預測誤差結果與圖4、圖5的預測結果很相似,誤差范圍仍然是±4°。
在機器人實驗平臺上驗證該神經網絡的性能時,以室內拍手聲作為聲源,大小約70 dB,背景噪聲約30 dB。機器人能辨別出聲源的方向并向其靠近,證明了該四元麥克風陣列可以使移動機器人實現較好的聲源定向和跟蹤。
本論文應用四元麥克風陣列進行移動機器人的聲源定向研究,設計了一個雙隱層的BP神經網絡。經Matlab仿真證明,輸入獲取的時延數據,可以實現近場和遠場的目標聲源定向,并且在機器人本體上進行了實驗測試,進一步驗證了其實用性。但是由于網絡擬合能力有限,并不能很好地預測聲源的空間距離,因此,如何實現對空間距離的準確預測是下一步的重點研究任務。
參考文獻
[1] 傅薈璇,趙紅. Matlab神經網絡應用設計[M]. 北京:機械工業出版社,2010.
[2]飛思科技產品研發中心. 神經網絡與Matlab 7實現[M].北京:電子工業出版社,2005.
[3] 周開利,康耀紅.神經網絡模型及其Matlab仿真程序設計[M]. 北京:清華大學出版社,2005.
[4] 張良均,曹晶,蔣世忠.神經網絡使用教程[M].北京:機械工業出版社,2008.
[5]吳仕勇. 基于數值計算方法的BP神經網絡及遺傳算法的優化研究[D].昆明:云南師范大學,2006.
[6] HAGAN M T, DEMUTH H B, BEALE M H. Neural network design[M]. 北京:機械工業出版社,2002.
[7] AARABI P, ZAKY S. Robust sound localization using multi-source audiovisual information fusion[J]. Information Fusion ,2001(2):209-223.
[8] LIN Z, XU B. Sound source localization based on microphone array[J].Electro-acoustic technology,2004(5):19-24.
[9] 余立雪.神經網絡與實例學習[M].北京:中國鐵道出版社,1996.