
摘 要: 研究了現有的調度算法,針對以出賣計算力為目的的網格,提出了基于冗余分配的調度模型,通過冗余分配實現了具有計算結果驗證功能的調度算法。對該算法中的預測器" title="預測器">預測器、資源信息服務" title="信息服務">信息服務、調度器" title="調度器">調度器" title="資源調度器" title="資源調度器">資源調度器">資源調度器及分配器進行了詳細介紹。
關鍵詞: 網格計算 任務調度" title="任務調度">任務調度 冗余分配 結果驗證
網格(Grid)是新一代的分布式計算環境與基礎設施,它提供無縫的、面向主題的全面資源共享和高性能計算。它向人類描繪了一臺虛擬的超級計算機畫面,整個網格就是一臺計算機,其資源可以取之不盡、用之不竭。目前,比較有影響的網格體系結構為國內的織女星網格體系結構[1]、五層沙漏結構[2]、開放網格服務體系結構[3](OGSA)和開放網格服務基礎結構[4](OGSI)。任務調度是這些體系結構中必不可少的環節,因為用戶的請求最終會被分置到網格的各資源節點上執行,從而最小化任務的執行時間,充分利用網格資源。
在網格計算中,通過對網格中計算力資源的整合,充分使用網格中的剩余計算力是一種最常見的利用資源的形式。在這種以出賣計算力為主的網格中,一個客戶無法知道陌生的遠端機計算出來的結果的正確性:有可能遠端機為了獲取經濟利益故意偽造結果;或是遠端主機本身的處理能力不夠,如產生了錯誤的浮點結果等[5]。本文針對該問題研究了現有的網格調度算法,并對以出賣計算力為主的網格提出了基于冗余分配的調度模型。
1 網格中的調度算法
任務調度是根據任務的信息和資源的信息采用適當的策略把不同的任務分配到合適的資源節點上運行的過程。網格中任務調度的特點為:
(1)導致網格資源異構并且狀態多變的因素主要有客觀和主觀兩方面。客觀上,網格是大范圍的環境,自然會有很多意外的情況發生,這要求調度中具有預測系統,通過資源的歷史記錄對其現況進行預測。主觀上,網格環境中大多數網格成員并不是專門為計算網格中的任務服務,只是提供部分計算力完成某些任務。資源的所有者并不希望它的資源專門為網格服務,因此會為自己的資源加上某些限制,如閑置周期以及用戶對資源的使用權限等。同時資源的所有者有其自身的本地任務,不可能為網格上的遠程任務提供完全的服務。在這種環境下的任務調度要復雜一些。
(2)由于任務對資源的需求各異,網格環境中的調度器必須綜合考慮應用和服務質量的約束,以獲得應用與資源之間較好的匹配,因此提出了基于服務質量的調度算法。這里服務質量的概念對于不同的資源可能有不同意義。例如,對于網絡資源,QoS可為提供給應用程序的可用帶寬;而對CPU資源,QoS意味著任務所想獲得的處理速度,如浮點運算速度[6]。
(3)現有的調度算法都是基于粗粒度,并且相互之間獨立或只有極少聯系的任務。因為若任務聯系過密,會導致通信量增加,反而使整個計算效率下降。這樣,適合于網格計算的通常是一些容易分割成相互獨立子任務的應用。
任務調度的基本思路可概括如下:
任務ti在機器mj的期望執行時間ETij(Expected Execution Time)定義為mj空載時執行ti的總時間。ti在機器mj的期望完成時間CTij定義為最終完成的時間(應包括完成其前面所有任務的時間)。設ai是ti的到達時間,bi是ti的開始時間,則CTij=bi+ETij。
常用的調度算法描述為:
(1) while there are tasks to schedule
(2) for all task i to schedule
(3) for all host j
(4) compute CTi,j=CT(task i,host j)
(5) end for
(6) compute metrici=f1(CTi,1,CTi,2,……)
(7) end for
(8) select best metric match(m,n)=f2(metric1,metric2……)
(9) compute minimum CTm,n
(10) schedule task m on n
(11) end while
算法需要不斷地計算未調度的任務的期望完成時間。(2)~(4)為計算每個任務在每個機器上的期望完成時間;(6)是按照某種評價方式f1對任務i在每臺機器上的期望完成時間得出其評價值metrici;(8)為使用某種標準f2在每個任務的評價值中找出符合標準要求的最優的任務與機器的匹配match(m,n);最后將任務m分配到機器n上執行。
例如,Min-min和Max-min算法定義評價方式f1為取最小的完成時間,即某個任務i的metric值為它在所有機器上的完成時間的最小值。不同的是,Min-min的標準f2是選擇metric值中的最小值,而Max-min是選擇最大值。
從上面的分析可以看出,一個好的調度取決于兩個方面,即對資源系統信息的預測及對應用程序(也可以認為是任務信息)的預測。資源系統的信息包括使用率、任務服務的速率、任務到達的速率等;應用程序的信息為工作量、可分割性、可并行性、完成時間等。一個關鍵的問題是:當為某些子任務指定的資源顯示出不正常的狀態時(從它的歷史數據中預測而得),如何保證并行應用的性能,即調度系統應在執行期間預測出資源的不正常狀態(如負載過重),重新安排調度。因此,一個調度算法是否成功取決于系統及應用狀態預測的精確度。這種預測是從其歷史信息中獲得的。
根據預測的性質可將調度分為兩種:一種是基于短期預測的調度,如AppLe項目使用了NWS服務提供的短期預測系統;另一種是基于長期預測的調度,采用這種方式的是GHS(Grid Harvest Service)。
2 基于冗余分配的調度算法
通過網格購買空閑的計算力有很大的發展前景,但這種方法很難保證所獲得的計算力能夠計算出正確的結果。這里提出冗余分配任務,使之在二個或多個節點上運行。其結果被多次驗證后認為是正確的。
調度模型由資源調度器、任務分配器、資源信息服務和預測器構成。資源調度器從現有網格中的節點資源中找出合適的節點集,它和資源信息服務配合使用;任務分配器將任務分配到節點集中;資源狀態預測需要消耗計算力,所以這里只做簡單預測,同時忽略對任務信息的預測。
2.1 預測器
這里對計算資源的狀況進行簡單的短期預測。預測由計算資源節點提供,目的是減輕資源調度器的負擔。
預測器收集節點自身信息并在資源調度器需要時給出預測值,它作為一個后臺程序一直運行在節點機上。一旦節點開始運行,就主動加入網格,提供自身的信息。預測器獲得系統的基本信息和可變信息。基本信息只需一次性獲得,在資源加入節點時提供給資源調度器;可變信息隨著時間變化,主要包括CPU的使用率和內存使用率。短期預測策略方式如下:
(1)設置一個線程,每隔1s收集一次動態信息,如CPU的使用率和內存的使用率。
(2)設置一個循環隊列,將一分鐘內的平均值不斷地寫入該隊列。
(3)當有預測需求時將隊列中的數值讀出再取其平均值作為預測值。例如,當隊列的大小設為5時就表示使用前五分鐘的平均值作為預測值。
2.2 資源信息服務
提供資源信息服務的是哈希表,該哈希表的信息組織形式如圖1所示。哈希表為調度器查找資源節點集提供依據。
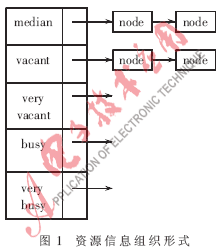
哈希表的key以節點狀態表示。因為節點狀態是時刻變化的,所以對節點可用性的描述不需要用十分精確的定量方式得出具體的數值,可采用模糊的定性的方式表述[7],即設置median、vacant、very vacant、busy、very busy五種狀態,以計算節點的性能參數wholePerformace作為分類標準。例如:wholePerformace>=85,其狀態為very busy;wholePerformace∈(60,85),為busy;wholePerformace∈[40,60],為median;wholePerformace∈(20,40),為vacant;whole-Performace∈[0,20],為very vacant。
2.3 資源調度器
調度器為某一應用找到合適的資源節點集。其策略為當要分配某一節點時再次獲取它的信息,以該最新信息作為調度的標準。描述如下:
(1)獲得應用的子任務數,并以其作為資源個數的最大請求數。
(2)在哈希表中從資源情況最好的隊列中開始查詢,如“very vacant”隊列。
(3)從該隊列中依次取節點,并依次與節點對應的計算資源聯系,以獲得其現有狀態。
(4)若該狀態差于該節點原來的狀態,則不分配該節點,并把它從現有的隊列中刪除,插入到與其狀態相一致的隊列中;若優于現有的狀態,則分配該節點,也把它從現有的隊列中刪除,插入到與其狀態相一致的隊列中;若等同于現有的狀態,則分配;若探測到該節點不可用(退出網格),則將其從隊列中刪除。
例如,一節點位于“very vacant”隊列,但在分配時查詢其性能參數值wholePerformace為50%,此時不分配該節點,同時將它從“very vacant”隊列刪除并插入到“median”隊列中。
(5)整個查詢結束的條件是:當找到子任務數個資源或是當資源數少于子任務數時,直接把所有的資源分給應用。
(6)當是單任務應用時,需找出兩個或多個資源。
2.4 分配器
(1)冗余分配
當分配器獲得合適的資源節點集后,就要決定如何安排子任務到各合適的機器上,以獲得最佳的性能。這里提出一種冗余分配策略,即將一個子任務分配到多個機器上執行。采取這種方式的原因是:
①在分配節點集的時候是一種模糊分配,因為對資源信息的描述采用定性的方式。
②在描述資源性能時并未考慮網絡的狀態而且未對應用程序信息做出預測。所以,在同一個狀態隊列中,性能參數wholePerformace大的計算節點的運算結果有可能先于性能參數wholePerformace小的到達。
③冗余分配可以實現冗余執行,冗余執行具有兩種功能。其一,如②所述,若將一個任務發送到多個節點執行,現狀最好的節點會最早將結果送回。這樣可以以較快的速度獲得結果,同時避免了只發送到一個計算節點的缺點:若出現意外情況,需要重新調度任務到節點。其二,冗余的執行可以實現結果驗證的功能。
(2)分配算法
分配器的算法描述如下:
對于每個子任務設置三個標志位:“分配狀態”,其值為整數,說明分配的次數,初值為0;“已獲得結果”,記錄獲得的資源節點計算的結果,若存在相等的結果,則為該子任務打上“刪除標記”。
分配器一開始將子任務隨機分配到調度器所找出的資源集上,分配狀態變為1;若有資源送回子任務的計算結果,則將該結果記錄到相應的標志位;若存在相等的結果,則為該子任務打上刪除標記,并且通知其他運行該任務的計算節點停止該任務的計算,若不存在,各標住位不能做任何改變;同時再次隨機選擇一個未打上刪除標記的子任務,將其分配到剛送回結果的計算資源上,分配狀態相應加1。整個分配結束的條件是所有的子任務都打上刪除標記。
3 算法性能評價
(1)減輕了預測的工作量。因為資源具有動態性,所以保留對資源的短期預測;因為適合網格計算的應用在劃分時很容易轉化為同樣大小的子任務,所以忽略對任務的預測。
(2)分配策略可以很好地支持動態性,即節點的動態退出。若某資源節點P1不知原因地退出了網格,如用戶誤操作、自身系統出問題等,則分配給它的子任務V1總是無法完成。但是按照分配策略,V1總會被分配在節點集的其他資源上執行,最終V1會被執行完。這時P1上V1的運行情況已經不重要了。
(3)調度器和分配器的協作達到了負載均衡的效果。若節點機P1負載小,則它的計算節點的性能參數小,獲得新任務的幾率大;當它的負載逐漸變大時,計算節點的性能參數也變大,獲得新任務的幾率變小,新的任務會向其他性能好的節點分配,同時在其任務隊列中的任務,也會因為任務在別處提前完成而被逐漸刪除。
(4)該算法適用于以計算為主的網格。以計算為主的應用結果容易比較,但有可能出現各機器精度不一致的情況。這時可以對所需要的精度范圍作出規定,對結果進行簡單處理后再比較。
本文給出了基于冗余分配的調度模型,適用于以出賣計算力為目的的網格。希望此算法能為今后的網格研究提供一定的思路。
參考文獻
1 徐志偉,李 偉.織女星網格的體系結構研究.計算機研究與發展,2002;39(8)
2 Foster J,Kesselman C,Tuecke S.The anatomy of the grid:Enabling scalable virtual organizations.International Journal Supercomputer Applicatins,2001;15(3)
3 Foster J,Kesselman C,Nick J M et al.The Physiology of the Grid:An Open Grid Services Architecture for Dist ributed Systems Integration.http://www.globus.org/research/papers/ogsa.pdf
4 Tuecke S,Czajkowski K,Foster L et al.Open Grid Services Inf rast ructure (OGSI).http://www.ggf.org/ogsi2wg,2003
5 Alexandrov A D,Ibel M,Schauser K E et al.SuperWeb:Re-search Issues in Java-Based Global Computing.http://www.citeseer.ist.psu.edu/alexandrov96superweb.html
6 HE X S,Sun X H,Laszewski G V.QoS Guided Min-Min Heuristic for Grid Task Scheduling.http://www.cs.iit.edu/~scs/psfiles/jcst_XHe-5-28.pdf
7 湯勇平.Java并行計算環境中的負載監測與預報系統.上海交通大學碩士論文集,2002